In “Configuration files and .d directories”, we learned how .d directories permit programmatic edits to system-wide configuration with ease. But this same concept—using directories with many individual files within instead of a single gigantic file—can be applied to other kinds of system-wide tracking.
I know it’s a stretch, but if it helps you in these modern times, you can think of a directory as a NoSQL database or a key/value store where each file represents a row/key and its contents represent the value of that entity. Adding and removing elements from the “database” is a matter of creating and deleting files, respectively, and retrieving elements can be done either by key lookup or by sequential scanning of the directory’s contents (though be aware that file systems don’t necessarily store entries in lexicographical order!).
We can take advantage of this core idea to represent system-wide databases while allowing them to be programmatically and concurrently mutated with ease. If we do this, just like we did for configuration files before, the packaging system can create and delete files on a package basis without having to do any file edits.
Easy, right? Yes, there is nothing more to it than this! But to keep you entertained, let me cover a bunch of different examples to see how this plays out in practice.
Application menus (via “menu” in Debian)
Quick: how is Debian able to automatically register new programs in the application menus displayed by pretty much any window manager? See, for example, this screenshot using the default Fluxbox configuration:
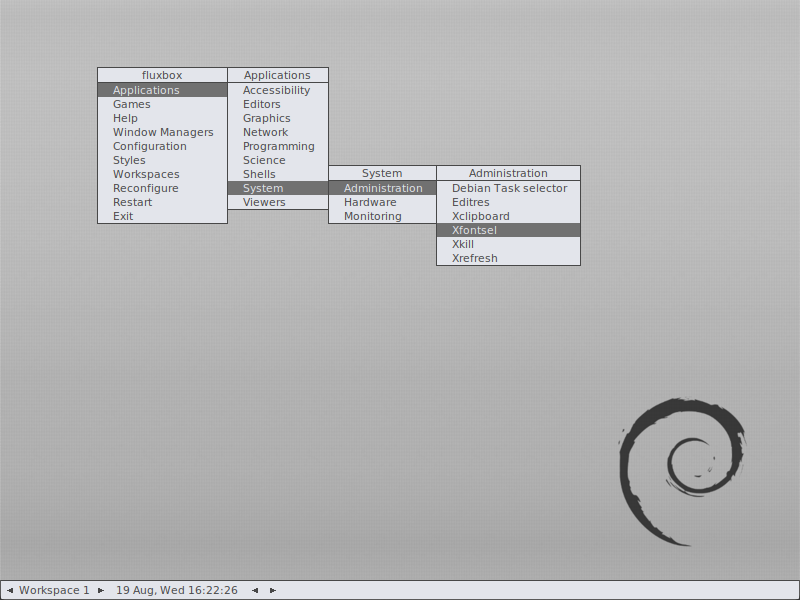
Generating menu entries might seem like a no-brainer today, but automatically updating these was a major difficulty years ago—and still is for some environments like Fluxbox. And I bet that’s why you might have never stopped to think about how this actually works, have you? 😉
To explain how this works, we have to travel back in time. Around the late 90s, we had a bunch of independent window managers and Gnome and KDE were still in their infancy. Each of these windowing systems had its own file format to represent application menus—yet Debian, somehow, was able to display up-to-date information about all available applications.
If you were designing Debian’s packaging system back in the day, how would you have achieved this? Stop and think for a minute before continuing.
As in anything computer-related, the answer is by adding an abstraction layer. In Debian, we have a tool called update-menus(1) that consumes a bunch of high-level definitions about installed programs and spits out generated menus in the formats that all supported window managers consume. For example, the bash package installs these entries:
debian:~> cat /usr/share/menu/bash
?package(bash):needs="text" section="Applications/Shells" title="Bash" command="/bin/bash --login"
?package(bash):needs="text" section="Applications/Shells" title="Sh" command="/bin/sh --login"
debian:~>
Based on a collection of files like this, all under the /usr/share/menu/ database, the package manager runs a post-installation trigger that executes update-menus(1) for all of the installed window managers and updates their menus in a consistent manner. In Fluxbox’s case, this action regenerates /etc/X11/fluxbox/menudefs.hook with fresh information.
Application menus (via FreeDesktop’s spec)
Debian’s menu package is all good and dandy, but it is system-specific and, to my surprise, it doesn’t seem to be widely used any longer within Debian any more.
Note that the reason I’m picking on Debian is, simply put, because I understand how it works. I’m sure other major systems like Fedora have their own mechanism to achieve these same results… but I did not research how they work for this article. Which reminds me that, in the early 2000s, I came up with my own solution to this problem for NetBSD with menu2wm. Luckily, I concluded that this was a dead end due to what we are about to see, but I’m not sure why I decided to shut down the code repositories!
Anyhow. Let’s switch gears to modern menu generation as used in KDE:
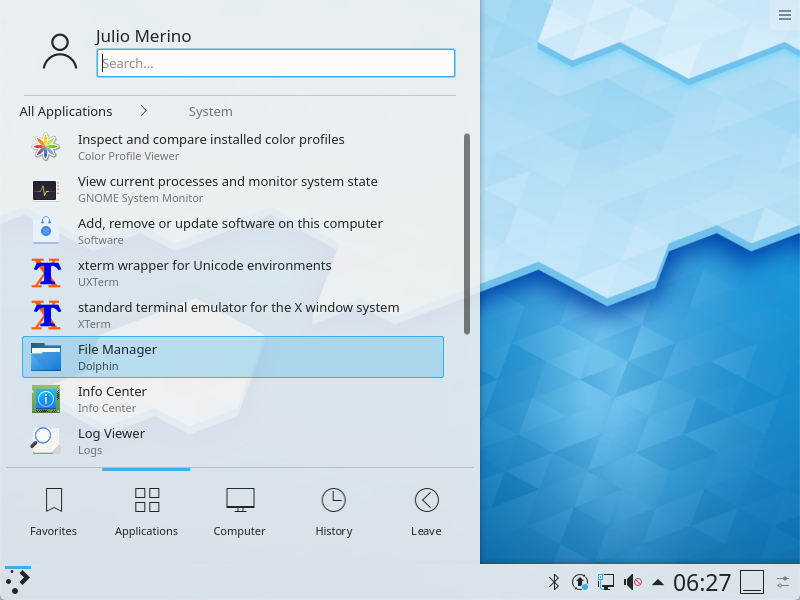
The way this works is by using /usr/share/applications/ as a database of menu entries. Each package that wants to register an entry in the system menus installs a .desktop file under this directory. These are very popular as my rather limited Debian installation shows:
debian:/usr/share/applications> ls -1 | wc -l
240
debian:/usr/share/applications>
These .desktop files essentially indicate the name of an app, the command to run it, the location where it should appear within the menus, and any file types that the app can handle. These files follow Freedesktop’s Desktop Entry Specification and a trivial example might look like this:
# Subset of /usr/share/applications/org.kde.dolphin.desktop without internationalization.
[Desktop Entry]
Name=Dolphin
GenericName=File Manager
Exec=dolphin %u
Terminal=false
Type=Application
Icon=system-file-manager
Categories=Qt;KDE;System;FileTools;FileManager;
MimeType=inode/directtory;
This file registers an entry for the Dolphin file manager and I’ll reference it in the rest of this section.
As we might expect, this file is owned by a unique package so it will be cleaned up if we ever uninstall it and thus removed from the system menus:
debian:~> dpkg-query -S /usr/share/applications/org.kde.dolphin.desktop
dolphin: /usr/share/applications/org.kde.dolphin.desktop
debian:~>
Desktop environments monitor this directory for changes (via inotify or kqueue, for example) and are able to reflect software additions and removals almost instantaneously.
But back then, Freedesktop was primarily about interoperability between KDE and Gnome, not arbitrary window managers as far as I understand it. So the question is: are .desktop files usable outside of these two major desktops? And the answer is: indeed they are! In fact, let’s look at a few examples to see how they all look relatively similar:
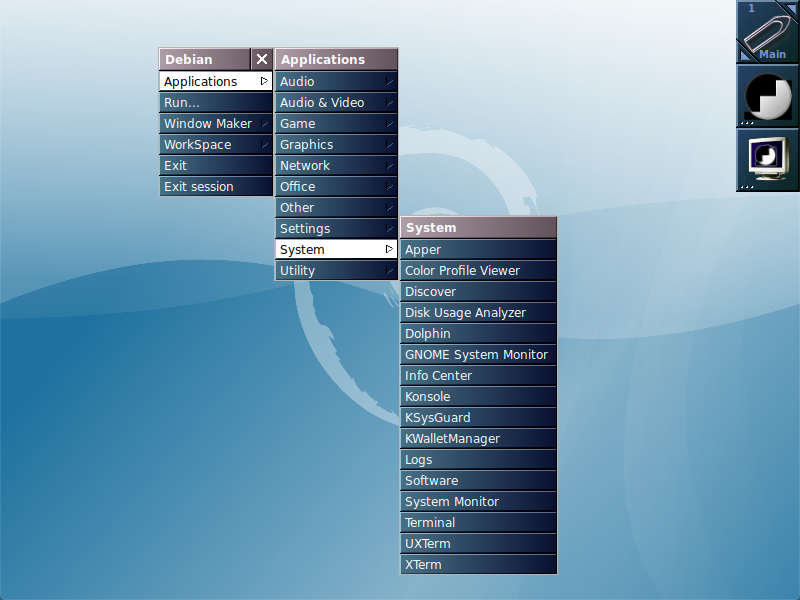
In WindowMaker’s case, we can find that it recognizes .desktop entries by means of an auxiliary tool called wmmenugen that parses them and outputs entries for WindowMaker’s root menu:
debian:~> grep -B 2 wmmenugen /usr/share/WindowMaker/menu.hook
Applications,
OPEN_PLMENU,
"|| wmmenugen -parser:xdg /usr/share/applications/"
debian:~>
Note also how the menu entry for our sample Dolphin program shows up exactly under the System submenu, just like KDE placed it. But is this categorization always the same? Not really:
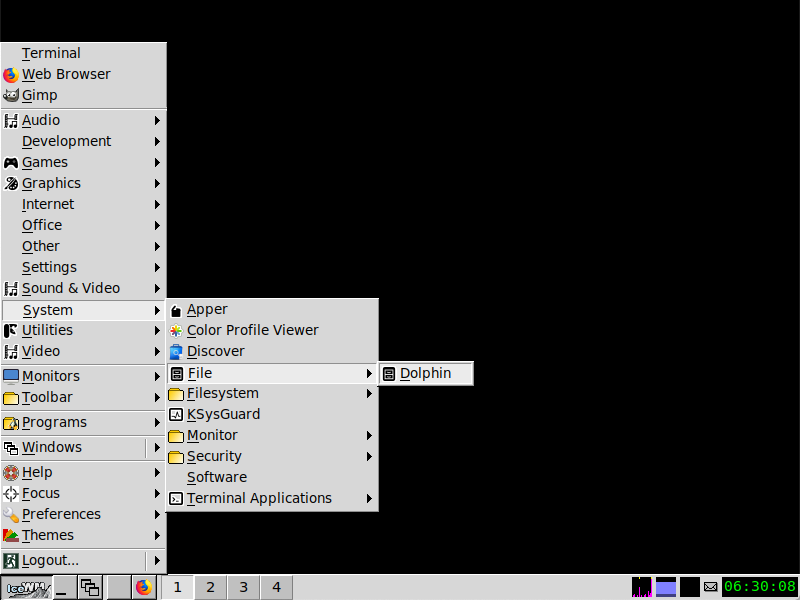
In IceWM’s case, Dolphin also shows up under the System submenu, but it is further nested under a File subsubmenu. Why? I’m not sure given that the File literal doesn’t even appear in the org.kde.dolphin.desktop file manager, but we can continue looking around.
If we poke through the default configuration for IceWM, we see that this window manager also comes with a helper tool to generate menu entries: icewm-menu-fdo. We can trivially invoke it from the command line to see what it outputs:
debian:~> icewm-menu-fdo | grep -A 1 -B 1 Dolphin
menu "File" system-file-manager {
prog "Dolphin" system-file-manager dolphin
}
debian:~>
But we still don’t have our answer about that File subsubmenu. We could probably search for the icewm-menu-fdo code to see what it does, but instead let’s look at one more window manager. Awesome shows the same Dolphin entry under a submenu titled System Tools, not System as we had seen until now:
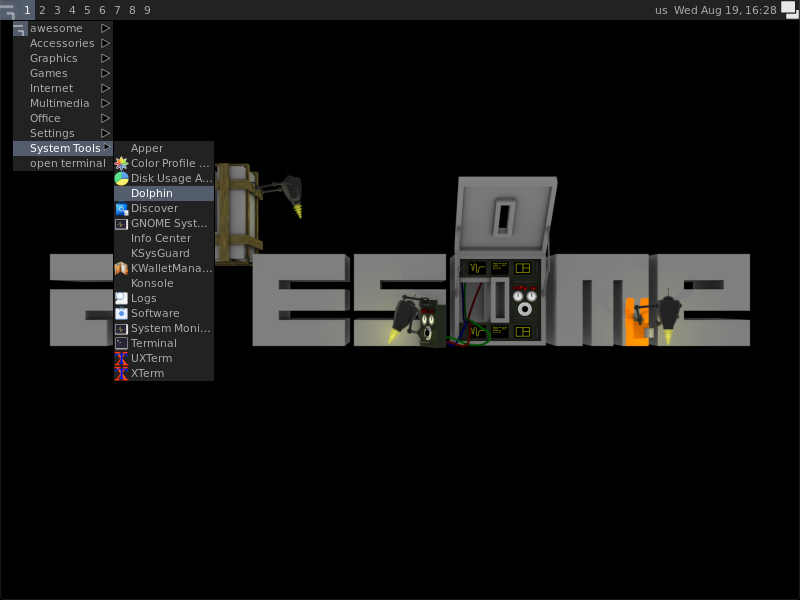
The plot thickens. I suppose the difference in menu names is because the tools generating the menus have a builtin mapping to match the Categories specified in the .desktop file to the specific layout they want to expose.
Awesome makes this easy to check because it seems to implement all .desktop file parsing in its Lua configuration, so we can comb through the logic without having to hunt for the source code. In particular, we can look at the /usr/share/awesome/lib/menubar/menu_gen.lua and /usr/share/awesome/lib/freedesktop/menu.lua files to chase how this works. And if we run a quick search:
debian:/usr/share/awesome/lib> grep -A 1 -r 'System Tools'
menubar/menu_gen.lua: tools = { app_type = "System", name = "System Tools",
menubar/menu_gen.lua- icon_name = "applications-system", use = true },
debian:/usr/share/awesome/lib>
We see that, indeed, the menu generation code has a mapping in it that matches apps with the System category (which was a literal in the .desktop file) to a menu titled System Tools.
Enough about menus and GUIs. Let’s dive into lower-level system constructs.
Compile-time lib details (via pkgconfig)
In the same vein as application discovery, we have the problem of library discovery. When you are building a piece of software, how can that software detect and determine how to link against pre-installed system-supplied libraries?
In the past, Makefiles would hardcode various -I, -L, and -l flags to cope with common system settings… but this didn’t scale across Unix flavors. autoconf came along with macros to auto-discover where libraries live but that was still insufficient because, to link against a library, determining the value of those flags can be difficult. Just think that the basename of an installed library may differ across systems, because why not, or it might require different threading flags.
So: what if we tried to have a central database that tracks how to link against each system-provided library? Then our autoconf scripts would simply query this database, get the flags from it, and go their merry way.
And that’s precisely what pkgconfig files do. These little .pc files, stored under /usr/share/pkgconfig/ and other confusing locations like /usr/lib/x86_64-linux-gnu/pkgconfig, do exactly the same as .desktop files but for libraries. If you want to link against a specific library, all you need to know is what name was used for its pkgconfig file and then look for that key.
For example, if we are interested in linking against glib2, we can do something like this to get the needed flags to compile and link against glib2:
debian:~> pkg-config --cflags glib-2.0
-I/usr/include/glib-2.0 -I/usr/lib/x86_64-linux-gnu/glib-2.0/include
debian:~> pkg-config --libs glib-2.0
-lglib-2.0
debian:~>
And once we have a database of installed libraries and tools, why not abuse it to supply arbitrary compile-time information to other packages? We can look at the udev.pc file, which contains zero traces of compiler or linker flags:
Name: udev
Description: udev
Version: 246
udev_dir=/lib/udev
udevdir=${udev_dir}
In this case, autoconf scripts might still want to know where udev stores system-wide information. And we can indeed extract that detail from this file:
debian:~> pkg-config --variable=udevdir udev
/lib/udev
debian:~>
The elephant in the room is “why pkgconfig”. After all, your system almost-certainly has its own package management tool. dpkg in Debian and rpm in Fedora (RedHat back then, actually) could have also been used to query details about installed system components. I’m guessing it was easier to introduce a separate system years ago that worked across systems than trying to thread this information through all possible package managers in all Linux distributions in a way that was easy to query.
Package metadata
Speaking about package managers, these also tend to be a notable adopter of the “directories as databases” concept. To find a prime example, we can look at pkgsrc’s database of installed packages. In my macOS system this lives under /opt/pkg/libdata/pkgdb/. What’s inside?
macos:/opt/pkg/libdata/pkgdb> ls -dF *lib*
gettext-lib-0.20.2/ libffi-3.3nb2/ libtool-base-2.4.6nb2/
glib2-2.64.2nb1/ libogg-1.3.4nb1/ libuv-1.38.0/
libarchive-3.4.3/ libsamplerate-0.1.9/ libvorbis-1.3.6nb1/
libcares-1.16.1/ libsass-3.6.4/ libxml2-2.9.10nb2/
libevent-2.1.11nb1/ libsndfile-1.0.28nb3/
macos:/opt/pkg/libdata/pkgdb>
I restricted the listing above to just libraries to make it more manageable, but we can easily see that we have one directory per installed package, and that the directory name encodes the package name and its version.
If we look into any one of these directories, we see a collection of plain text files that supply additional information for that package:
macos:/opt/pkg/libdata/pkgdb> ls -F libevent-2.1.11nb1
+BUILD_INFO +CONTENTS +REQUIRED_BY
+BUILD_VERSION +DESC +SIZE_ALL
+COMMENT +INSTALLED_INFO +SIZE_PKG
macos:/opt/pkg/libdata/pkgdb>
Conceptually, and further extending our databases analogy, you can think of these files as being columns in our table of installed package. In this model, each row in the table corresponds to a package and matches a directory name. For each row, we then have separate columns for the package’s build details (+BUILD_INFO and +BUILD_VERSION), the package’s user-friendly description (+COMMENT and +DESC), etc.
The good thing about a database like this is that it’s very transparent. There is nothing unfathomable about it: you can manually look at the files and understand what’s going on, and if anything ever gets corrupted (which sometimes happens, unfortunately), you can perform manual surgery to try to recover the system.
Which brings us to my last example…
Going on a tangent: svn and git
Version control systems (VCSs) are no exception here, though they are a bit off-topic because they aren’t system-wide databases.
VCSs have also used plain files and directories as their backing store for ages, going back to CVS and possibly more. But let’s focus on a couple more modern systems by starting with Subversion.
If memory serves well, the first versions of Subversion used an actual database, BDB, to store the repository. This was a huge departure from CVS’ plain files model and caused discomfort to system administrators: “What if the database gets corrupted?” “Can we trust Subversion enough, still in beta, to do the right thing?” With CVS, we could do manual file recovery and repository-level hand-edits (common to scrub sensitive data).
As a result of this, the Subversion developers wrote FSFS, an alternate backend for their database that uses plain files in a directory. There we have it once again: a directory used as a database! We can easily create one and check its contents for entertainment, but I won’t get into the details here:
debian:~> svnadmin create /tmp/repo && cd /tmp/repo
debian:/tmp/repo> ls -F
README.txt conf/ db/ format hooks/ locks/
debian:/tmp/repo> ls -F db
current fsfs.conf revs/ txn-current-lock write-lock
format min-unpacked-rev transactions/ txn-protorevs/
fs-type revprops/ txn-current uuid
debian:/tmp/repo> ls -F db/revs
0/
debian:/tmp/repo>
And to conclude, let’s just say that Git follows this same idea:
debian:~> mkdir /tmp/repo && cd /tmp/repo && git init --bare
Initialized empty Git repository in /tmp/repo/
debian:/tmp/repo> ls -F
HEAD branches/ config description hooks/ info/ objects/ refs/
debian:/tmp/repo>
Parting words
As we have seen, when you start looking around, you will find examples of databases represented as a collection of files and directories everywhere. Whether that’s a good idea or not… depends.
Using the file system as a database is a very powerful construct. From a package management perspective, where you want different packages updating a central repository of information (like those menu entries, pkgconfig files, or configuration), this model is probably the best choice. Also, for tools where you want full transparency on how the backing store works (version control systems), this is possibly also a good choice.
But the file system is limited and can be a very poor database! Locking is hard. Indexes require extra logic and might get out of sync. Transactions require additional brittle logic too. So if you need anything fancier and don’t need to support multiple writers with different implementations, you should really use a proper database. SQLite is small and can do wonders.

