In software engineering organizations, there are certain practices that keep costs under control even if those seem more expensive at first. Unfortunately, because such practices feel more expensive, teams choose to keep their status quo even when they know it is suboptimal. This choice ends up hurting productivity and morale because planned work is continuously interrupted, which in turn drags project completion.
The reason I say seem and not are is because the alternatives to these cost-exposing practices also suffer from costs. The difference is that, while the former surface costs, leading to the need to allocate time and people to infrastructure work, the latter keeps the costs smeared over teams and individuals in ways that are difficult to account and plan for.
To illustrate what I’m trying to say, I’ll present three different scenarios in which this opinion applies. All of these case studies come from past personal experiences while working in different teams and projects. The first one covered in this post is about the adoption of a monorepo vs. the use of multiple different repositories. The other two will come in follow-up articles.
A blog on operating systems, programming languages, testing, build systems, my own software projects and even personal productivity. Specifics include FreeBSD, Linux, Rust, Bazel and EndBASIC.
![]()
![]()
![]()
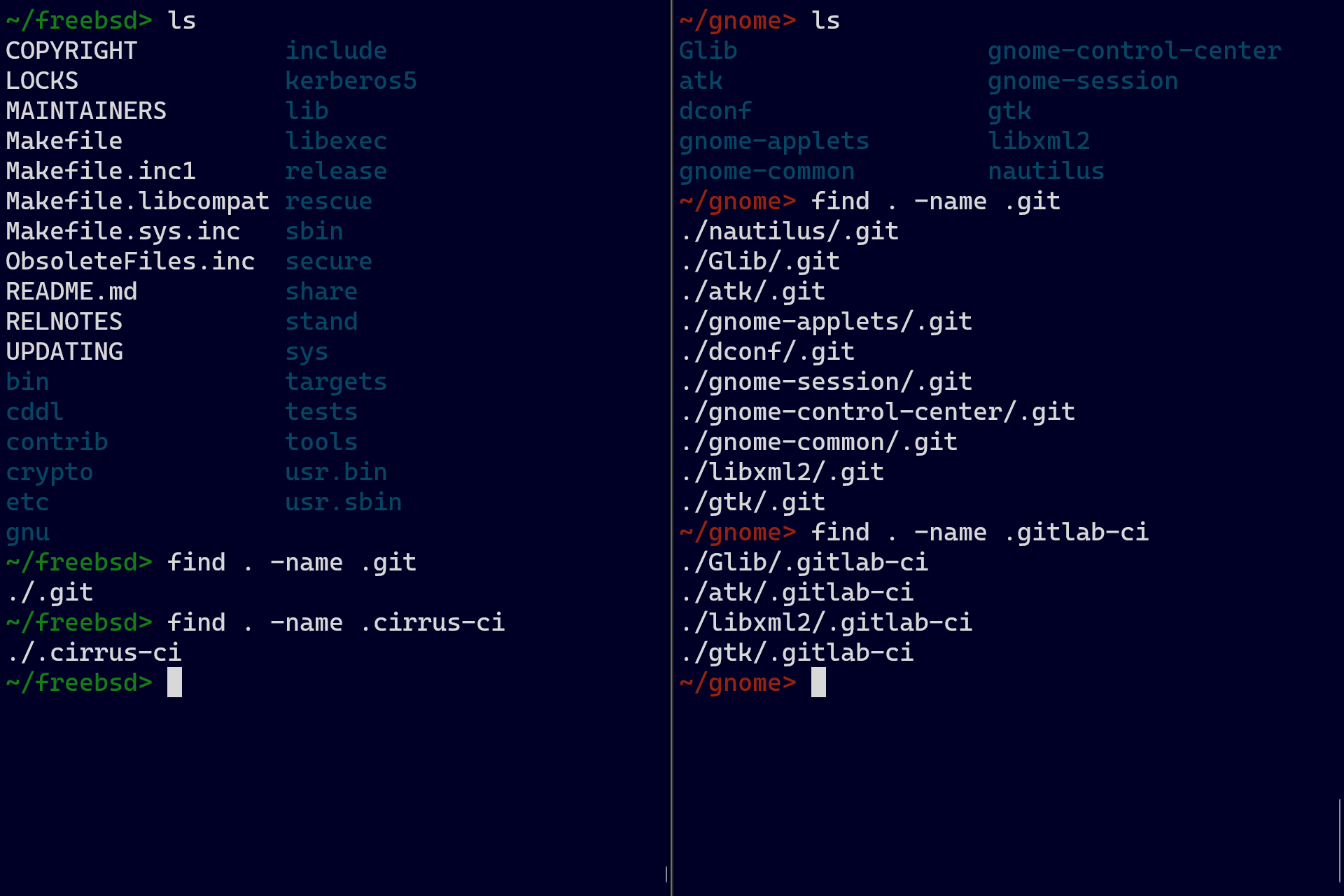
Monorepos are in fashion. In fact, I like to think that they have been a good idea for large organizations since before Google made them popular: the BSDs have followed this model from their inception in the 1970s even if the “monorepo” term wasn’t coined yet. But I’m not writing about this topic just because of the BSDs. I’m writing about this topic because I previously worked at Google, and Google made the conscious choice to fund a monorepo for the benefit of everyone in the company. I’m writing about this because I also worked in the Azure Storage team, which ran a monorepo and a bunch of ancillary repos but with a small team to support them. And I’m writing about this because I’m now at Snowflake, helping with the adoption of monorepo tooling with a well-staffed team.
Adopting a monorepo can bring advantages such as code sharing, unified tooling, and a standardized development experience. However, monorepos are also visibly expensive. And because they seem expensive, cost is often an objection to adopting one. And for good reason: if you decide to migrate to a monorepo without proper funding to maintain the build system, the language toolchains, the CI system, the release process, the practices to follow, etc. the monorepo will eventually collapse under its own weight.
What’s not so obvious—and what the objectors are missing—is that these maintenance costs exist in multirepo environments too. The difference is that, in multirepo setups, these costs fly under the radar because they are smeared across every repo. When taken individually, the costs seem insignificant, but in unison, they make a taxing impact on every team member.
Here is what happens in the typical multirepo scenario: different teams own different repos and are responsible for their maintenance. Two arguments that arise in their favor when proposing a switch to a monorepo are:
“Repo maintenance is a shared responsibility. We should all care about their health!”
When ownership is shared… nobody owns anything. When the repos are small and the teams are small, there is no designated individual to mend them. Build breakages will arise, modernization changes will be necessary, flaky tests will grow out of control… and at some point, when things have gotten so bad that productivity grinds to a halt, “someone” will have to do something.
Who will? In the best case, the “person or people that care” will take it upon themselves to resolve these issues in their “free time”. But because maintaining the repository is not their primary job, these issues will be preempting their assigned tasks. In the worst case… well, there is nobody that cares or nobody with the expertise to do anything, thus the problems may go unfixed or they may be “fixed” in a haphazard way, causing toil for everyone else.
“These side repos are not that important… don’t waste time on them!”
Eventually, though, some repos become more important than others: maybe because they are used more, maybe because they contain the majority of the company’s product code, or maybe because your ongoing migration to the monorepo stops halfway through.
The important repos see more care in their tooling—they probably have a dedicated team to maintain them—but the others lag behind. Maybe these side repos get stuck with an old version of the compiler because upgrading them wasn’t done in the past and doing so now is difficult. Maybe they do not have the right PR validation checks set up, which causes their tests to rot. Maybe there are no enforced coding standards, so their contents are a mess. Maybe they just are different than the main repo—different build system, different language—requiring a different skillset to interact with them.
Whatever the reasons are, these side repos are full of sharp corners that slow down any activities to change them. People dread doing such changes or they do the wrong thing because there is no incentive to keep things tidy.
While these arguments in defense of monorepos sound reasonable, they end up causing a continuous drag on team productivity and morale. When engineers work with suboptimal tooling day in and day out without any clear path to make things better, they grow disillusioned with the engineering practices and will eventually want to jump ship.
Compare these issues to a monorepo setup: when the infrastructure breaks, it is clear which team to call; after all, it is their mandate to budget time to fix problems and to plan and execute major quality-of-life improvements. And when the infrastructure team performs a change, the change benefits everyone without requiring all of the smaller teams to do anything on their own. As an engineer, it is much easier to feel accomplished due to the larger-scope task and it is easier to justify impact at performance review time.
The costs that the monorepo brings to light are clear, while the costs of the multirepo approach are pushed under the rug and slowly become a source of toil paid by all teams. This toil usually falls under the radar because there is no single front-line manager that can assess the systemic problems company-wide, so the problems never get resolved. And because every team is only impacted “a little bit”, it is difficult to quantify how much this type of toil costs in terms of productivity in the organization.
So, while adopting a monorepo isn’t the right choice for everyone, do not glance over the option to migrate to one just because you think it’s more expensive to run. Look at your current practices and see how much effort your engineers waste dealing with suboptimal tooling because nobody has the chance to make things better in a significant manner.
And if you do decide to migrate to a monorepo without knowing any of this upfront, know that these cost issues become obvious really quickly because the monorepo helps expose them. Once that happens, you’ll have to staff teams to manage these problems. And if done right, those teams will have well-defined charters and full responsibility for their part of the monorepo experience. As you move towards the monorepo, you’ll see time freed from everyone not directly responsible for the monorepo maintenance.
Still not convinced? Stay tuned for the next part, in which I will look into the costs that different ticket assignment practices have in on-call rotations.

