

If you read my previous article on DOS memory models, you may have dismissed everything I wrote as “legacy cruft from the 1990s that nobody cares about any longer”. After all, computers have evolved from sporting 8-bit processors to 64-bit processors and, on the way, the amount of memory that these computers can leverage has grown orders of magnitude: the 8086, a 16-bit machine with a 20-bit address space, could only use 1MB of memory while today’s 64-bit machines can theoretically access 16EB.
All of this growth has been in service of ever-growing programs. But… even if programs are now more sophisticated than they were before, do they all really require access to a 64-bit address space? Has the growth from 8 to 64 bits been a net positive in performance terms?
Let’s try to answer those questions to find some very surprising answers. But first, some theory.
Code density
An often overlooked property of machine code is code density, a loose metric that quantifies how many instructions are required to execute a given “action”. I double-quote action because an “action” in this context is a subjective operation that captures a programmer-defined outcome.
Suppose, for example, that you want to increment the value of a variable that resides in main memory, like so:
static int a;
// ...
a = a + 1;
On a processor with an ISA that provides complex instructions and addressing modes, you can potentially do so in just one machine instruction:
; Take the 32-bit quantity at the address indicated by the
; 00001234h immediate, increment it by one, and store it in the
; same memory location.
add dword [1234h], 1
In contrast, on a processor with an ISA that strictly separates memory accesses from other operations, you’d need more steps:
li r8, 1234h ; Load the address of the variable into r8.
lm r1, r8 ; Load the content of the address into r1.
li r2, 1 ; Load the immediate value 1 into r2.
add r3, r1, r2 ; r3 = r1 + r2
sm r8, r3 ; Store the result in r3 into the address in r8.
Which ISA is better, you ask? Well, as usual, there are pros and cons to each approach:
The former type of ISA offers a denser representation of the operation so it can fit more instructions in less memory. But, because of the semantic complexity of each individual instruction, the processor has to do more work to execute them (possibly requiring more transistors and drawing more power). This type of ISA is usually known as CISC.
The latter type of ISA offers a much more verbose representation of the operation but the instructions that the processor executes are simpler and can likely be executed faster. This type of ISA is usually known as RISC.
This is the eternal debate between CISC and RISC but note that the distinction between the two is not crystal clear: some RISC architectures support more instructions that CISC architectures, and contemporary Intel processors translate their CISC-style instructions into internal RISC-style micro-operations immediately after decoding the former.
It’s the bytes that matter
Code density is not about instruction count though. Code density is about the aggregate size, in bytes, of the instructions required to accomplish a specific outcome.
In the example I presented above, the single CISC-style mov x86 instruction is encoded using anywhere from 2 to 8 bytes depending on its arguments, whereas the fictitious RISC-style instructions typically take 4 bytes each. Therefore, the CISC-style snippet would take 8 bytes total whereas the RISC-style snippet would take 20 bytes total, while achieving the same conceptual result.
Is that increase in encoded bytes bad? Not necessarily because “bad” is subjective and we are talking about trade-offs here, but it’s definitely an important consideration due to its impact in various dimensions:
Memory usage: Larger programs take more memory. You might say that memory is plentiful these days, and that’s true, but it wasn’t always the case: when computers could only address 1 MB of RAM or less, the size of a program’s binary mattered a lot. Furthermore, even today, memory bandwidth is limited, and this is an often-overlooked property of a system.
Disk space: Larger programs take more disk space. You might say that disk space is plentiful these days too and that program code takes a tiny proportion of the overall disk: most space goes towards storing media anyway. And that’s true, but I/O bandwidth is not as unlimited as disk space, and loading these programs from disk isn’t cheap. Have you noticed how utterly slow is it to open an Electron-based app?
L1 thrashing: Larger or more instructions mean that you can fit fewer of them in the L1 instruction cache. Proper utilization of this cache is critical to achieve reasonable levels of computing performance, and even though main memory size can now be measured in terabytes, the L1 cache is still measured in kilobytes.
We could beat the dead horse over CISC vs. RISC further but that’s not what I want to focus on. What I want to focus on is one very specific dimension of the instruction encoding that affects code density in all cases. And that’s the size of the addresses (pointers) required to reference program code or data.
Simply put, the larger the size of the addresses in the program’s code, the lower the code density. The lower the code density, the more memory and disk space we need. And the more memory code takes, the more L1 thrashing we will see.
So, for good performance, we probably want to optimize the way we represent addresses in the code and take advantage of surrounding context. For example: if we have a tight loop like this:
static int a;
...
for (int i = 0; i < 100; i++) {
a = a + 1;
}
The corresponding assembly code may be similar to this:
mov ecx, 0 ; i = 0.
repeat: cmp ecx, 100 ; i < 100?
je out ; If i == 100, jump to out.
add dword [01234h], 1 ; Increment a.
add ecx, 1 ; i++.
jmp repeat ; Jump back to repeat.
out:
Now the questions are:
Given that
repeatandoutare labels for memory addresses, how do we encode theje(jump if equal) andjmp(unconditional jump) instructions as bytes? On a 32-bit machine, do we encode the full 32-bit addresses (4 bytes each) in each instruction, or do we use 1-byte relative short pointers because the jump targets are within a 127-byte distance on either side of the jump instruction?How do we represent the address of the
avariable? Do we express it as an absolute address or as a relative one? Do we store1234has a 32-bit quantity or do we use fewer bytes because this specific number is small?How big should
intbe? Thedwordabove implies 32 bits but… that’s just an assumption I made when writing the snippet.intcould have been 16 bits, or 64 bits, or anything else you can imagine (which is a design mistake in C, if you ask me).
The answers to the questions above are choices: we can decide whichever encoding we want for code and data addresses, and these choices have consequences on code density. This was true many years ago during the DOS days, which is why we had short, near, and far pointer types, and is still true today as we shall see.
The switch to 32 bits
It is no secret that programming 16-bit machines was limiting, and we can identify at least two reasons to back this claim.
First, 16-bit machines usually had limited address spaces. It’s important to understand that a processor’s native register size has no direct connection to the size of the addresses the processor can reference. In theory, these machines could have leveraged larger chunks of memory and, in fact, the 16-bit 8086 proved this to be true with its 20-bit address space. But the point is that, in the era of 16-bit machines, 1 MB of RAM was considered “a lot” and so machines didn’t have much memory.
Second, 16-bit machines can only operate on 16-bit quantities at a time, and 16 bits only allow representing integers with limited ranges: a signed number between -32K and +32K isn’t… particularly large. Like before, it’s important to clarify that the processor’s native register size does not impose restrictions on the size of the numbers the processor can manipulate, but it does add limitations on how fast it can do so: operating 32-bit numbers on 16-bit machines requires at least twice the number of instructions for each operation.
So, when 32-bit processors entered the scene, it was pretty much a no-brainer that programs had to become 32-bit by default: all memory addresses and default integer types grew to 32 bits. This allowed programmers to not worry about memory limits for a while: 32 bits can address 4GB of memory, which was a huge amount back then and should still be huge if it wasn’t due to bloated software. Also, this upgrade allowed programmers to efficiently manipulate integers with large-enough ranges for most operations.
In technical mumbo-jumbo, what happened here was that C adopted the ILP32 programming model: integers (I), longs (L), and pointers (P) all became 32 bits, whereas chars and shorts remained 8-bit and 16-bit respectively.
It didn’t have to be this way though: if we look at the model for 16-bit programming, shorts and integers were 16-bit whereas longs were 32-bit, so why did integers change size but longs remained the same as integers? I do not have an answer for this, but if longs had become 64 bits back then, maybe we wouldn’t be in the situation today where 2038 will bring mayhem to Unix systems.
Evolving towards x86-64
4GB of RAM were a lot when 32-bit processors launched but slowly became insufficient as software kept growing. To support those needs, there were crutches like Intel’s PAE, which allowed manipulating up to 64GB of RAM on 32-bit machines without changing the programming model, but they were just that: hacks.
The thing is: it’s not only software that grew. It’s the kinds of things that people wanted to do with software that changed: people wanted to edit high-resolution photos and video as well as play more-realistic games, and writing code to achieve those goals on a limited 4GB address space was possible but not convenient. With 64-bit processors, mmaping huge files made those programs easier to write, and using native 64-bit integers made them faster too. So 64-bit machines became mainstream sometime around the introduction of the Athlon 64 processor and the Power Mac G5, both in 2003.
So what happened to the programming model? ILP32 was a no-brainer for 32-bit machines, but were LP64 or ILP64 no-brainers for 64-bit machines? These 64-bit models were definitely tempting because they allowed the programmer to leverage the machine’s resources freely. Larger pointers allowed addressing “unlimited” memory transparently, and a larger long type naturally bumped file offsets (ino_t), timestamps (time_t), array lengths (size_t), and more to 64 bits as well. Without a lot of work from programmers, programs could “just do more” by simply recompiling them.
But there was a downside to that choice. According to the theory I presented earlier, LP64 would make programs bigger and would decrease code density when compared to ILP32. And lower code density could lead to L1 instruction cache thrashing, which is an important consideration to this day because a modern Intel Core i7-14700K from 2023 has just 80 KB of L1 cache and an Apple Silicon M3 from 2023 has less than 200KB. (These numbers are… not big when you stack them up against the multi-GB binaries that comprise modern programs, are they?)
We now know that LP64 was the preferred choice and that it became the default programming model for 64-bit operating systems, which means we can compare its impact against ILP32. So what are the consequences? Let’s take a look.
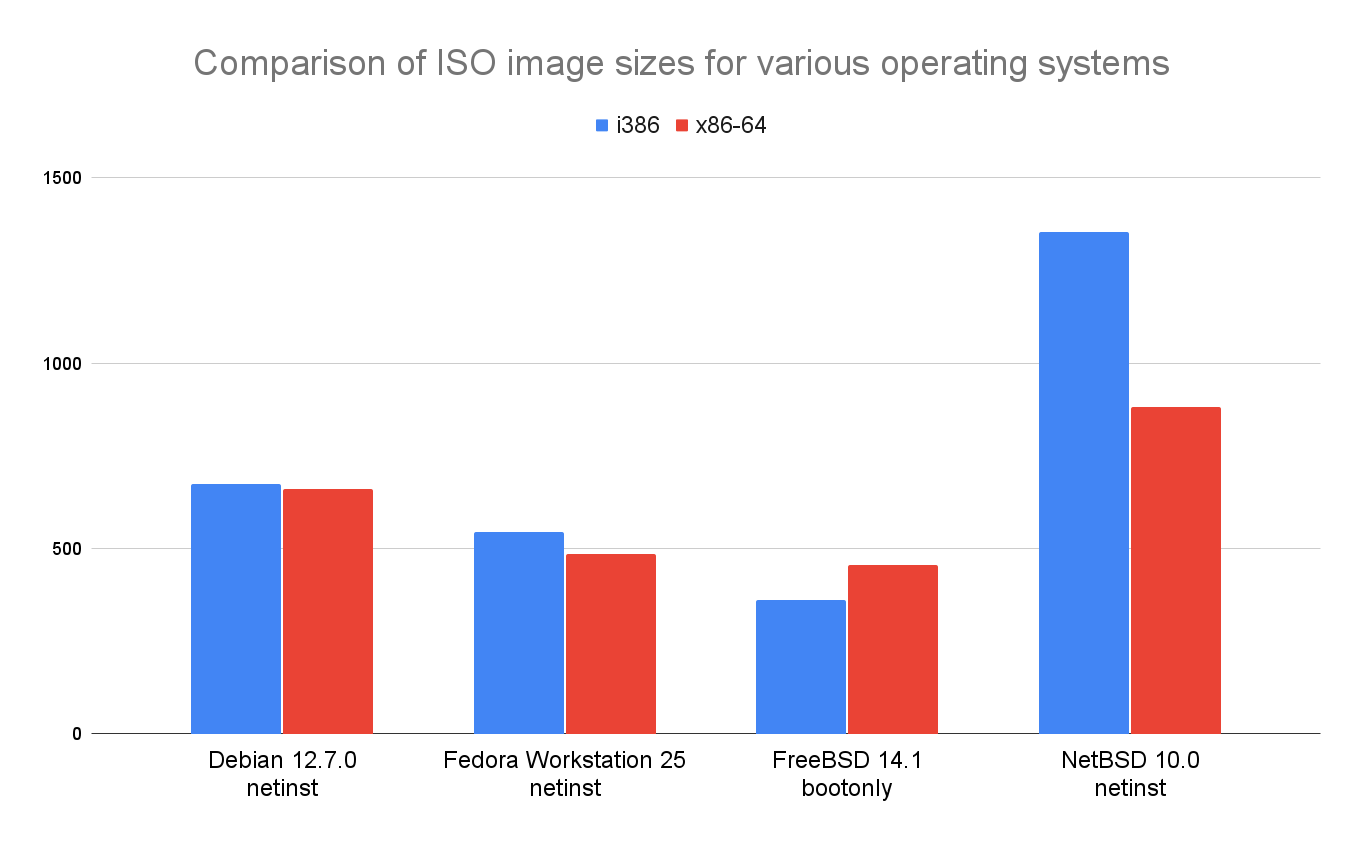
Wait, what? The FreeBSD x86-64 installation image is definitely larger than the i386 one… but all other images are smaller? What’s going on here? This contradicts everything I said above!
Down the rabbit hole
I was genuinely surprised by this and I had to dig a bit. Cracking open the FreeBSD bootonly image revealed some differences in the kernel (slightly bigger binaries, but different sets of modules) which made it difficult to compare the two. But looking into the Debian netinst images, I did find that almost all i386 binaries were larger than their x86-64 counterparts.
To try to understand why that was, the first thing I did was compile a simple hello-world program on my x86-64 Debian VM, targeting both 64-bit and 32-bit binaries:
$ gcc-14 -o hello64 hello.c
$ i686-linux-gnu-gcc-14 -o hello32 hello.c
$ file hello32 hello64
hello32: ELF 32-bit LSB pie executable, Intel 80386, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux.so.2, for GNU/Linux 3.2.0, not stripped
hello64: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=f1bf851d7f1d56ae5d50eb136793066f67607e06, for GNU/Linux 3.2.0, not stripped
$ ls -l hello32 hello64
-rwxrwxr-x 1 jmmv jmmv 15040 Oct 4 17:45 hello32
-rwxrwxr-x 1 jmmv jmmv 15952 Oct 4 17:45 hello64
$ █
Based on this, it looks as if 32-bit binaries are indeed smaller than 64-bit binaries. But a “hello world” program is trivial and not worth 15kb of code: those 15kb shown above are definitely not code. They are probably mostly ELF overhead. Indeed, if we look at just the text portion of the binaries:
$ objdump -h hello32 | grep text
14 .text 00000169 00001060 00001060 00001060 2**4
$ objdump -h hello64 | grep text
14 .text 00000103 0000000000001050 0000000000001050 00001050 2**4
$ █
… we find that hello32’s text is 169h bytes whereas hello64’s text is 103h bytes. And if we disassemble the two:
$ objdump --disassemble=main hello32
...
00001189 <main>:
1189: 8d 4c 24 04 lea 0x4(%esp),%ecx
118d: 83 e4 f0 and $0xfffffff0,%esp
1190: ff 71 fc push -0x4(%ecx)
1193: 55 push %ebp
1194: 89 e5 mov %esp,%ebp
1196: 53 push %ebx
1197: 51 push %ecx
1198: e8 28 00 00 00 call 11c5 <__x86.get_pc_thunk.ax>
119d: 05 57 2e 00 00 add $0x2e57,%eax
11a2: 83 ec 0c sub $0xc,%esp
11a5: 8d 90 14 e0 ff ff lea -0x1fec(%eax),%edx
11ab: 52 push %edx
11ac: 89 c3 mov %eax,%ebx
11ae: e8 8d fe ff ff call 1040 <puts@plt>
11b3: 83 c4 10 add $0x10,%esp
11b6: b8 00 00 00 00 mov $0x0,%eax
11bb: 8d 65 f8 lea -0x8(%ebp),%esp
11be: 59 pop %ecx
11bf: 5b pop %ebx
11c0: 5d pop %ebp
11c1: 8d 61 fc lea -0x4(%ecx),%esp
11c4: c3 ret
...
$ objdump --disassemble=main hello64
...
0000000000001139 <main>:
1139: 55 push %rbp
113a: 48 89 e5 mov %rsp,%rbp
113d: 48 8d 05 c0 0e 00 00 lea 0xec0(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1144: 48 89 c7 mov %rax,%rdi
1147: e8 e4 fe ff ff call 1030 <puts@plt>
114c: b8 00 00 00 00 mov $0x0,%eax
1151: 5d pop %rbp
1152: c3 ret
...
$ █
We observe massive differences in the machine code generated for the trivial main function. The 64-bit code is definitely smaller than the 32-bit code, contrary to my expectations. But the code is also very different; so different, in fact, that ILP32 vs. LP64 doesn’t explain it.
The first difference we can observe is around calling conventions. The i386 architecture has a limited number of registers, favors passing arguments via the stack, and only 3 registers can be clobbered within a function. x86-64, on the other hand, prefers passing arguments through registers as much as possible and defines 7 registers as volatile.
The second difference is that we don’t see 64-bit addresses anywhere in the code above. Jump addresses are encoded using near pointers, and data addresses are specified as offsets over a 64-bit base previously stored in a register. I found it smart that those addresses are relative to the program counter (the RIP register).
There may be more differences, but these two alone seem to be the reason why 64-bit binaries end up being more compact than 32-bit ones. On Intel x86, that is. You see: Intel x86’s instruction set is so versatile that the compiler and the ABI can play tricks to hide the cost of 64-bit pointers.
Is that true of more RISC-y 64-bit architectures though? I installed the PowerPC 32-bit and 64-bit toolchains and ran the same test. And guess what? The PowerPC 64-bit binary was indeed larger than the 32-bit one, so maybe it’s true. Unfortunately, running a broader comparison than this is difficult: there is no full operating system I can find that ships both builds any longer, and ARM images can’t easily be compared.
It’s all about the data
OK, fine, we’ve settled that 64-bit code isn’t necessarily larger than 32-bit code, at least on Intel, and thus any adverse impact on the L1 instruction cache is probably negligible. But… what about data density?
Pointers don’t only exist in instructions or as jump targets. They also exist within the most modest of data types: lists, trees, graphs… all contain pointers in them. And in those, unless the programmer explicitly plays complex tricks to compress pointers, we’ll usually end up with larger data structures by simply jumping to LP64. The same applies to the innocent-looking long type by the way, which appears throughout codebases and also grows with this model.
And this—a decrease in data density—is where the real performance penalty comes from: it’s not so much about the code size but about the data size.
Let’s take a look. I wrote a simple program that creates a linked list of integers with 10 million nodes and then iterates over them in sequence. Each node is 8 bytes in 32-bit mode (4 bytes for the int and 4 bytes for the next pointer), whereas it is 16 bytes in 64-bit mode (4 bytes for the int, 4 bytes of padding, and 8 bytes for the next pointer). I then compiled that program in 32-bit and 64-bit mode, measured it, and ran it:
$ gcc -o list64 list.c
$ i686-linux-gnu-gcc-14 -o list32 list.c
$ objdump -h list32 | grep text
13 .text 000001f6 00001070 00001070 00001070 2**4
$ objdump -h list64 | grep text
14 .text 000001b0 0000000000001060 0000000000001060 00001060 2**4
$ hyperfine --warmup 1 ./list32 ./list64
Benchmark 1: ./list32
Time (mean ± σ): 394.2 ms ± 2.1 ms [User: 311.4 ms, System: 83.1 ms]
Range (min … max): 392.1 ms … 398.2 ms 10 runs
Benchmark 2: ./list64
Time (mean ± σ): 502.4 ms ± 4.5 ms [User: 334.9 ms, System: 167.8 ms]
Range (min … max): 494.9 ms … 509.5 ms 10 runs
Summary
./list32 ran
1.27 ± 0.01 times faster than ./list64
$ █
As before with the hello-world comparison, this simple microbenchmark’s 32-bit code continues to be slightly larger than its 64-bit counterpart (1F6h bytes vs 1B0h). However, its runtime is 27% faster, and it is no wonder because the doubling of the linked list node size implies doubling the memory usage and thus the halving of cache hits. We can confirm the impact of this using the perf tool:
$ perf stat -B -e cache-misses ./list32 2>&1 | grep cpu_core
2,400,339 cpu_core/cache-misses:u/ (99.33%)
$ perf stat -B -e cache-misses ./list64 2>&1 | grep cpu_core
4,687,156 cpu_core/cache-misses:u/ (99.34%)
$ █
The 64-bit build of this microbenchmark incurs almost double the cache misses than the 32-bit build.
Of course, this is just a microbenchmark, and tweaking it slightly will make it show very different results and make it say whatever we want. I tried to add jitter to the memory allocations so that the nodes didn’t end up as consecutive in memory, and then the 64-bit version executed faster. I suspect this is due to the memory allocator having a harder time handling memory when the address space is limited.
The impact on real world applications is harder to quantify. It is difficult to find the same program built in 32-bit and 64-bit mode and to run it on the same kernel. It is even more difficult to find one such program where the difference matters. But at the end of the day, the differences exist, and I bet they are more meaningful than we might think in terms of bloat—but I did not intend to write a research paper here, so I’ll leave that investigation to someone else… or another day.
The x32 ABI
There is one last thing to discuss before we depart. While we find ourselves using the LP64 programming model on x86-64 processors, remember that this was a choice and there were and are other options on the table.
Consider this: we could have made the operating system kernel leverage 64 bits to gain access to a humongous address space, but we could have kept the user-space programming model as it was before—that is, we could have kept ILP32. And we could have gone even further and optimized the calling conventions to reduce the binary code size by leveraging the additional general-purpose registers that x86-64 provides.
And in fact, this exists and is known as x32.
We can install the x32 toolchain and see that it effectively works as we’d imagine:
$ gcc -o hello64 hello.c
$ x86_64-linux-gnux32-gcc-14 -o hellox32 hello.c
$ objdump --disassemble=main hello64
...
0000000000001139 <main>:
1139: 55 push %rbp
113a: 48 89 e5 mov %rsp,%rbp
113d: 48 8d 05 c0 0e 00 00 lea 0xec0(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1144: 48 89 c7 mov %rax,%rdi
1147: e8 e4 fe ff ff call 1030 <puts@plt>
114c: b8 00 00 00 00 mov $0x0,%eax
1151: 5d pop %rbp
1152: c3 ret
...
$ objdump --disassemble=main hellox32
...
00401126 <main>:
401126: 55 push %rbp
401127: 89 e5 mov %esp,%ebp
401129: b8 04 20 40 00 mov $0x402004,%eax
40112e: 89 c0 mov %eax,%eax
401130: 48 89 c7 mov %rax,%rdi
401133: e8 f8 fe ff ff call 401030 <puts@plt>
401138: b8 00 00 00 00 mov $0x0,%eax
40113d: 5d pop %rbp
40113e: c3 ret
...
$ █
Now, the main method of our hello-world program is really similar between the 64-bit and 32-bit builds, but pay close attention to the x32 version: it uses the same calling conventions as x86-64, but it contains a mixture of 32-bit and 64-bit registers, delivering a more compact binary size.
Unfortunately:
$ ./hellox32
zsh: exec format error: ./hellox32
$ █
We can’t run the resulting binary. x32 is an ABI that impacts the kernel interface too, so these binaries cannot be executed on a regular x86-64 kernel. Sadly, and as far as I can tell, x32 is pretty much abandonware today. Gentoo claims to support it but there are no official builds of any distribution I can find that are built in x32 mode.
In the end, even though LP64 wasn’t the obvious choice for x86-64, it’s the compilation mode that won and stuck.


Featured software
Featured posts
- Fast machines, slow machines
- EndBASIC 0.10: Core language, evolved
- Farewell, Microsoft; hello, Snowflake!
- Rust is hard, yes, but does it matter?
- Rust traits and dependency injection
- A year on Windows: Introduction
- Always be quitting
- How does Google keep build times low?
- How does Google avoid clean builds?
- Unit-testing a console app (a text editor)
- More...