

Two and a half years ago, I joined Snowflake to help their mission of migrating to Bazel. I spent the first year of this period as an Individual Contributor (IC) diving deep into the migration tasks, and then I took over the Tech Lead (TL) role of the team to see the project through completion.
This week, we publicly announced that we completed our migration to Bazel for the largest part of our codebase and we provided details on our journey. I did not publish that article here for obvious reasons, so… today’s entry is going to be a light one: all I want to do is point you at our announcement as well as the various other related articles that came before it.
Don’t despair though: those articles, including the announcement, are all full of technical details—just like the kind of content you expect to receive from Blog System/5. So, even if this piece is light, you have enough reading material for the weekend via the links below.
“Addressing Bazel OOMs”
March 16th, 2023

This was the very first article that we in the Engineering Systems organization—previously known as Developer Productivity Engineering—wrote publicly about our work. Me writing it was no coincidence as I was the one advocating for more openness about the cool stuff we were doing. Yes, I missed blogging about Bazel as I had done in the years prior.
In this article about Out-Of-Memory (OOM) conditions, I covered the very interesting problem of trying to fit Bazel builds into limited laptop resources. This was déjà-vu for me: back when I was in the Blaze team at Google, I owned the same problem of making Blaze, a tool that had grown assuming massive workstations, run decently on machines with limited resources.
The problems were technically challenging and worth talking about, hence this article. In it, I covered three issues: preventing Bazel from spawning too many memory-hungry compilers and linkers at once; making nested builds behave nicely; and tuning Bazel to drive a large number of remote tasks with limited memory resources.
“Analyzing OOMs in IntelliJ with Bazel”
October 6th, 2023
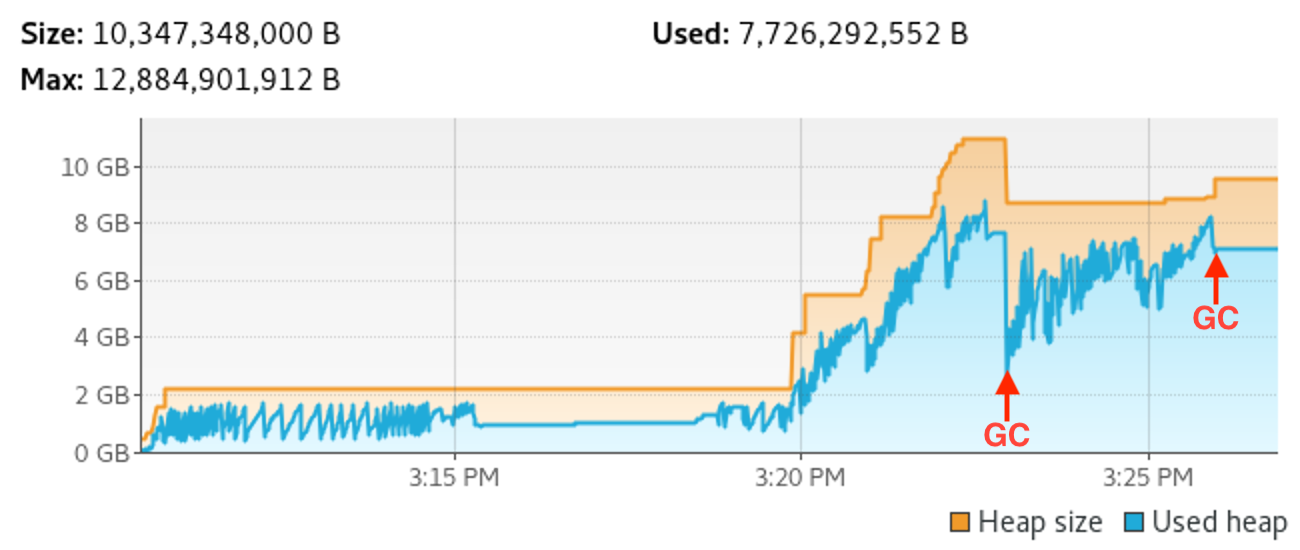
Our saga dealing with OOMs was arduous and long, which you can tell by the time gap between the previous article and this one.
In this piece, I looked at how IntelliJ itself was running into memory limits, which resulted in the IDE and its container VM freezing during normal operation. The result of this work was careful tuning of the Bazel project settings to make it fit within reasonable limits, but the interesting part—and the one described here—was the process to arrive to those findings.
Not too long after I wrote this, we pivoted away from constrained laptop builds to cloud-based workstations, which made all OOM conditions vanish at the expense of using much more RAM (maybe too much RAM, but alas… it’s cheap). Stay tuned for an upcoming article (not from me this time!) on this topic.
“Build farm visualizations”
October 20th, 2023

As part of our migration to Bazel, we didn’t just convert our build from one tool to another. We also decided to deploy our own remote execution cluster from the get go based on Buildbarn which… gave us its own set of problems. Buildbarn’s architecture is straightforward in paper, but there are a ton of knobs to control how it runs. Making it scale to the huge volume of traffic we experience was not an easy feat.
One specific problem we faced was overall poor performance of our cluster, which was eventually root-caused to our remote execution workers using slow local storage volumes. This issue had escaped us for a while, and it wasn’t until I wrote a tool to visualize the cluster behavior that it didn’t become obvious. From there, the solution was easy.
Wanna know more? We are hosting a 1-day conference next week on Buildbarn specifically. See the schedule and sign up if you can make it!
“Fast and Reliable Builds at Snowflake with Bazel”
March 13th, 2025

And finally, the crown jewel. This is the official article published just yesterday where I present the 2-year journey of our migration. In it, I explain the challanges that we faced with our C++ and Java codebases specifically, the choices behind our use of remote execution, and the path we took to production. I conclude with a glimpse on what lies ahead of us.
That’s all for today. I promised it would be short :)
