

The previous article on Bazel remote caching concluded that using just a remote cache for Bazel builds was suboptimal due to limitations in what can and cannot be cached for security reasons. The reason behind the restrictions was that it is impossible to safely reuse a cache across users. Or is it?
In this article, we’ll see how leveraging remote execution in conjunction with a remote cache opens the door to safely sharing the cache across users. The reason is that remote execution provides a trusted execution environment for actions, and this opens the door to cross-user result sharing. Let’s see why and how.
Remote execution basics
As we saw in the article about action determinism, Bazel’s fundamental unit of execution is the action. Consequently, a remote execution system is going to concern itself with efficiently running individual actions, not builds, and caching the results of those. This distinction is critical because there are systems out there that work differently, such as Microsoft’s CloudBuild, Buildbuddy’s Remote Bazel, or even the shiny and new Bonanza.
When we configure remote execution via the --remote_executor flag, Bazel enables the remote action execution strategy by default for all actions, just as if we had done --strategy=remote. But this is only a default and users can mix-and-match remote and local strategies by leveraging the various --strategy* selection flags or by specifying execution requirements in individual actions.
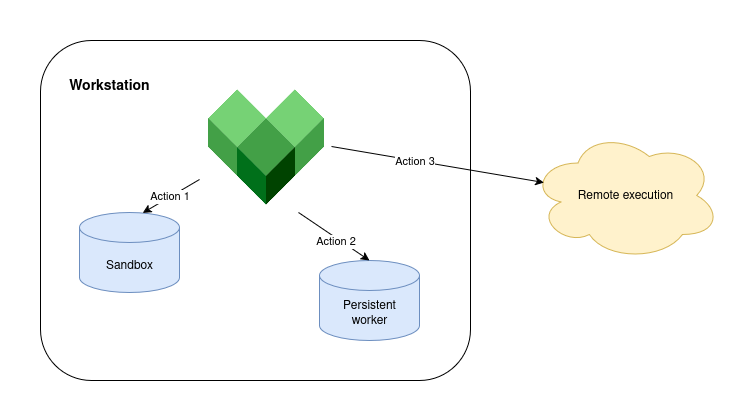
A remote execution system is complicated as it is typically implemented by many services:
Multiple frontends. These are responsible for accepting user requests and tracking results. These might include implement a second-level CAS to fan out traffic to clients.
A scheduler. This is responsible for enqueuing action requests and distributing them to workers. Whether the scheduler uses a pull or push model to distribute work is implementation dependent.
Multiple workers. These are responsible for action execution and are organized in pools of distinct types (workers for x86, workers for arm64, etc.) Internally, a worker is divided into two conceptual parts: the worker itself, which is the privileged service that monitors action execution, and the runner, which is a containerized process that actually runs the untrusted action code.
The components of a remote cache (a CAS and an AC). The CAS is essential for communication between Bazel and the workers. The AC, which is optional, is necessary for action caching. The architecture of the cache varies from service to service.
For the purposes of this article, I want to focus primarily on the workers and their interactions with the AC and the CAS. I’m not going to talk about frontends nor schedulers except for showing how they help isolate remote action execution from the Bazel process.
Worker and AC/CAS interactions
Let’s look at the interaction between these components in more detail. To set the stage, take a look at the combine action from this sample build file:
genrule(
name = "generate",
outs = ["gen.txt"],
cmd = "echo generated >$@",
)
genrule(
name = "combine",
outs = ["combined.txt"],
srcs = [":src.txt", ":gen.txt"],
cmd = "cat $(location :src.txt) $(location :gen.txt) >$@",
)
The combine action has two types of inputs: a checked-in source file, src.txt, and a file generated during the build, gen.txt. This distinction is interesting because the way these files end up in the CAS is different: Bazel is the one responsible for uploading src.txt into the CAS, but gen.txt is uploaded by the worker upon action completion.
When we ask Bazel to build //:combine remotely, and assuming //:generate has already been built and cached at some point in the past, we’ll experience something like this:
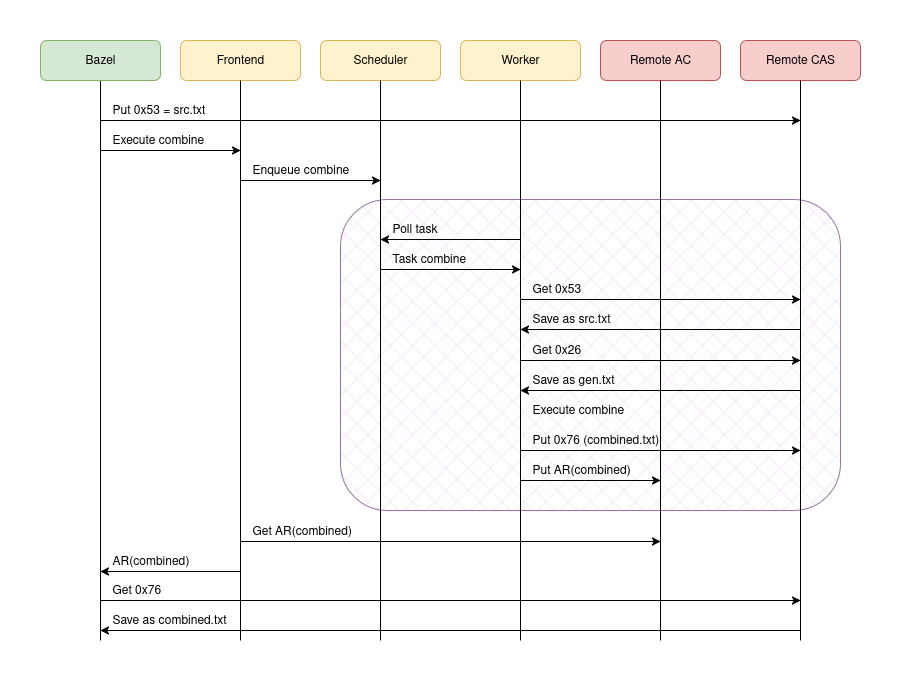
That’s a lot of interactions, right?! Yes; yes they are. A remote execution system is not simple and it’s not always an obvious win: coordinating all of these networked components is costly. The overheads become tangible when dealing with short-lived actions—a better fit for persistent workers—or when you have a sequential chain of actions—a good fit for the dynamic execution strategy.
What I want you to notice here, because it’s critical for our analysis, is the shaded area. Note how all interactions within this area are driven by the remote execution service, not Bazel. Once an action enters the remote execution system, neither Bazel nor the machine running Bazel have any way of tampering with the execution of the remote action. They cannot influence the action’s behavior, and they cannot interfere with the way it saves its outputs into the AC and the CAS.
And this decoupling, my friend, is the key insight that allows Bazel to safely share the results of actions across users no matter who initiated them. However, the devil lies in the implementation details.
Securing the worker
Given the above, we now know that remote workers are a trusted environment: the actions that go into a worker are fully specified by their action key and, therefore, whatever they produce and is stored into the AC and the CAS will match that action key. So if we trust the inputs to the action, we can trust its outputs, and we can do this retroactively… right?
Well, not so fast. For this to be true, actions must be deterministic, and they aren’t always as we already saw. Some sources of non-determinism are “OK” in this context though, like timestamps, because these come from within the worker and cannot be tampered with. Other sources of non-determinism are problematic though, like this one:
genrule(
name = "generate",
outs = ["gen.txt"],
cmd = "curl -L https://secure.example.com/payload.txt >$@",
)
An attacker could compromise the network request to modify the content of the downloaded file, but only for long enough to poison the remote cache with a malicious artifact. Once poisoned, they could restore the remote file to its original content and it would be very difficult to notice that the entry in the remote cache did not match the intent of this rule.
It is tempting to say: “ah, the above should be fixed by ensuring the checksum of the download is valid”, like this:
genrule(
name = "generate",
outs = ["gen.txt"],
cmd = """
curl -L https://secure.example.com/payload.txt >$@
[ "$$(sha256sum $@ | awk '{print $1}')" = "known checksum" ]
""",
)
And I’d say, yes, you absolutely need to do checksum validation because there are legitimate cases where you’ll find yourself writing code like this… in repo rules. Unfortunately, such checks are still insufficient for safe remote execution because, remember: actions can run from unreviewed code, or the code that runs them can be merged into the tree after a careless review (which is more common than you think). Consequently, the only thing you can and must do here is to disable network access in the remote worker.
That said, just disabling network access may still be “not good enough” to have confidence in the safety of remote execution. A remote execution system is trying to run untrusted code within a safe production environment: code that could try to attack the worker to escape whatever sandbox/container you have deployed, code that could try to influence other actions running on the same machine, or code that could exfiltrate secrets present in the environment. Securing these is going to come down to standard practices for untrusted code execution, none of which are specific to Bazel, so I’m not going to cover them. Needless to say, it’s a difficult problem.
Securing the build
If we have done all of the above, we now have a remote execution system that we can trust to run actions in a secure manner and to store their results in both the AC and the CAS. But… this, on its own, is still insufficient to secure builds end-to-end, and we would like to have trusted end-to-end builds to establish a chain of trust between sources and production artifacts, right?
To secure a build, we must protect the AC and restrict writes to it to happen exclusively from the remote workers. Only them, who we have determined cannot be interfered with, know that the results of an action correspond to its declared inputs—and therefore, only them can establish the critical links between an AC entry and one or more files in the CAS. You’d imagine that simply setting --noremote_upload_local_results would be enough, but it isn’t. A malicious user could still tamper with this flag in transient CI runs or… well, in their local workstation. And it’s because of this latter scenario that the only possible way to close this gap is via network level ACLs: the AC should only be writable from within the remote execution cluster.
But… you guessed it: that’s still insufficient. Even if we disallow Bazel clients from writing to the AC, an attacker can still make Bazel run malicious actions outside of the remote execution cluster—that is, on the CI machine locally, which does have network access. Such action wouldn’t record its result in the AC, but the output of the action would go into the CAS, and this problematic action could then be consumed by a subsequent action as an input.
The problem here stems from users being able to bypass remote execution by tweaking --strategy* flags. One option to protect against this situation is the same as we saw before: disallow CI runs of PRs that modify Bazel flags so that users cannot “escape” remote execution. Unfortunately, this doesn’t have great ergonomics because users often need to change the .bazelrc file as part of routine operation.
Bazel’s answer to this problem is the widely-unknown invocation policy feature. I say unknown because I do not see it documented in the output of bazel help and I cannot find any details about it whatsoever online—yet I know of its existence from my time at Google and I see its implementation in the Bazel code base, so we can reverse-engineer how it works.
Invocation policies
As the name implies, an invocation policy is a mechanism to enforce specific command-line flag settings during a build or test with the goal of ensuring that conventions and security policies are consistently applied. The policy does so by defining rules to set, override, or restrict the values of flags, such as --strategy.
The policy is defined using the InvocationPolicy protobuf message defined in src/main/protobuf/invocation_policy.proto. This message contains a list of FlagPolicy messages, each of which defines a rule for a specific flag. The possible rules, which can be applied conditionally on the Bazel command being executed, are:
SetValue: Sets a flag to a specific value. You can control whether the user can override this value. This is useful for enforcing best practices or build-time configurations.UseDefault: Forces a flag to its default value, effectively preventing the user from setting it.DisallowValues: Prohibits the use of certain values for a flag. If a user attempts to use a disallowed value, Bazel will produce an error. You can also specify a replacement value to be used instead of the disallowed one.AllowValues: Restricts a flag to a specific set of allowed values. Any other value will be rejected.
To use an invocation policy, you have to define the policy as an instance of the InvocationPolicy message in text or base64-encoded binary protobuf format and pass the payload to Bazel using the --invocation_policy flag in a way that users cannot influence (e.g. directly from your CI infrastructure, not from workflow scripts checked into the repo).
Let’s say you want to enforce a policy where the --genrule_strategy flag is always set to remote when running the bazel test command, and you want to prevent users from overriding this setting. We define the following policy in a policy.txt file:
flag_policies: {
flag_name: "genrule_strategy"
commands: "build"
set_value: {
flag_value: "remote"
behavior: FINAL_VALUE_THROW_ON_OVERRIDE
}
}
And then we invoke Bazel like this (again, remember: this flag should be passed by CI in a way that users cannot influence):
bazel --invocation_policy="$(cat policy.txt)" build ...
If you now try to play with the --genrule_strategy flag, you’ll notice that any overrides you provide don’t work. (Bazel 9 will offer a new FINAL_VALUE_THROW_ON_OVERRIDE flag behavior to error out instead of silently ignoring overrides which will make the experience nicer in this case.)
Case study: remote local fallback poisoning
Before concluding, I’d like to show you an interesting outage we faced due to Bazel being allowed to write AC entries from a trusted CI environment. The problem we saw was that, at some point, users started reporting that their builds were completely broken: somehow, the build of our custom singlejar helper tool, a C++ binary that’s commonly used in Java builds, started failing due to the inability of the C++ compiler to find some header files.
This didn’t make any sense. If we built the tree at a previous point in time, the problem didn’t surface. And as we discovered later, if we disabled remote caching on a current commit the problem didn’t appear either. Through a series of steps, we found that singlejar’s build from scratch would fail if we tried to build it locally without the sandbox. But… that’s not something we do routinely, so how did this kind of breakage leak into the AC?
The problem stemmed from our use of --remote_local_fallback, a flag we had enabled long ago to mitigate flakiness when leveraging remote execution. Because of this flag, we had hit this problematic path:
An build started on CI. This build used a remote-only configuration, forcing all actions to run on the remote cluster.
Bazel ran actions remotely for a while, but at some point, encountered problems while building singlejar.
Because of
--remote_local_fallback, Bazel decided to build singlejar on the CI machine, not on the remote worker, and it used thestandalonestrategy, not thesanboxedstrategy, to do so. This produced an action result that was later incompatible with sandboxed / remote actions.Because of
--remote_upload_local_results, the “bad” action result was injected into the AC.From here on, any remote build that picked the bad action result would fail.
The mitigation to this problem was to flush the problematic artifact from the remote cache, and the immediate solution was to set --remote_local_fallback_strategy=sandboxed which… Bazel claims is deprecated and a no-op, but in reality this works and I haven’t been able to find an alternative (at least not in Bazel 7) via any of the other strategy flags.
The real solution, however, is to ensure that remote execution doesn’t require the local fallback option for reliability reasons, and to prevent Bazel from injecting AC entries for actions that do not run in the remote workers.
Parting words
With that, this series to revisit Bazel’s action execution fundamentals, remote caching, and remote execution is complete. Which means I can finally tell you the thing that started this whole endeavor: the very specific, cool, and technical solution I implemented to work around a hole in the action keys that can lead to very problematic non-determinism.
But, to read on that topic, you’ll have to wait for the next episode!


Featured software
Featured posts
- Fast machines, slow machines
- EndBASIC 0.10: Core language, evolved
- Farewell, Microsoft; hello, Snowflake!
- Rust is hard, yes, but does it matter?
- Rust traits and dependency injection
- A year on Windows: Introduction
- Always be quitting
- How does Google keep build times low?
- How does Google avoid clean builds?
- Unit-testing a console app (a text editor)
- More...