
This article is not about AI and it is not written with AI, but the work that I’m about to present was definitely motivated by AI. And because I generally like telling stories, I have to give you that background. Do with that whatever you want, but… it’d be a pity if you left just because the AI word showed up in the first paragraph! I think the technical explanation that follows is at the very least entertaining and also interesting independently of AI.
Back in December, I started toying with coding agents. One thing I tried, and for which I didn’t expect a lot of success, was to point an AI agent to the EndBASIC public documentation and ask it to write games like Space Invaders or Mario from scratch. And even though the results weren’t perfect and they didn’t work on the first try, they did work with a few tiny tweaks. Combining that with a bunch of hand-written AGENTS.md rules, I had an agent producing EndBASIC demos with ease.
This experiment was impressive because I did not expect an agent to be able to write EndBASIC code… and because it worked, it fueled my interest to pick EndBASIC’s own development back up. Three thoughts came to mind:
- Increase EndBASIC’s “self-documenting” aspects so that an AI agent can learn about its idiosyncrasies unsupervised.
- Speed up EndBASIC so that it can run more elaborate games.
- Extend EndBASIC with long-desired primitives like sprites and sound, to finally realize the vision behind the project.
These thoughts combined sparked the rewrite of EndBASIC’s core that I’ve been pursuing since January and which should see the light of day in the upcoming release. But before that happens, I want to talk to you about just one of the cool pieces behind the new core: namely, its approach to testing. I’ve stopped writing unit tests for the compiler and VM in Rust and I’ve switched to writing them in Markdown. And I believe this has turned out to be a pretty nice approach.
So wait, why Markdown?
One of the things I had to do to convince an AI agent to write proper EndBASIC code was to hand-craft a bunch of AGENTS.md rules to tell it how EndBASIC differs from other, more traditional BASIC dialects. That worked OK, but writing these rules by hand was error-prone and difficult to make exhaustive. So I wanted to let LLMs extract that information directly from EndBASIC.
The idea was simple: if I wrote the integration tests for the new core in Markdown, the lingua franca of AI, the tests would serve as the canonical and correct documentation demonstrating language behaviors. LLMs are great at summarizing information, so if I unleashed them over a large set of these hands-on “examples”, they would probably figure stuff out, right?
And they actually do! I gave the following prompt to GPT 5.4:
Based on your pre-existing knowledge of BASIC dialects, I want you to read all of the
core/tests/*.mdfiles, analyze how the EndBASIC dialect differs from your knowledge, and come up with a bunch of rules for yourself to know how to write EndBASIC code later on. You can ignore the Disassembly sections.Beware that all functions and commands in these integration tests are test-only: the real functions and commands that you can use are documented in
cli/tests/repl/help.out, so read those too to learn what functionality is available.Write your findings to a
rules.mdfile.
And this produced a very comprehensive file with spot-on rules: here, take a look.
But leaving that aside, let’s peek into the internals of this new Markdown-based test suite.
What is a Markdown test suite?
It’s a collection of Markdown files:
endbasic$ ls -l core/tests/*.md | head -n 10
-rw-r--r-- 1 jmmv users 22771 May 11 14:18 core/tests/test_args.md
-rw-r--r-- 1 jmmv users 3785 May 11 13:22 core/tests/test_arithmetic_add.md
-rw-r--r-- 1 jmmv users 2653 May 11 13:22 core/tests/test_arithmetic_div.md
-rw-r--r-- 1 jmmv users 2668 May 11 13:22 core/tests/test_arithmetic_mod.md
-rw-r--r-- 1 jmmv users 2131 May 11 13:22 core/tests/test_arithmetic_mul.md
-rw-r--r-- 1 jmmv users 1466 May 11 13:22 core/tests/test_arithmetic_neg.md
-rw-r--r-- 1 jmmv users 2517 May 11 13:22 core/tests/test_arithmetic_pow.md
-rw-r--r-- 1 jmmv users 2208 May 11 13:22 core/tests/test_arithmetic_sub.md
-rw-r--r-- 1 jmmv users 20388 May 11 13:22 core/tests/test_arrays.md
-rw-r--r-- 1 jmmv users 5885 May 11 13:22 core/tests/test_assignments.md
endbasic$ █
Where each file acts as a container of one or more test cases:
endbasic$ grep '^# ' core/tests/test_end.md | head -n 5
# Test: Call to END and nothing else
# Test: Exit code is an integer immediate
# Test: Exit code is a double immediate and needs demotion
# Test: Exit code is in a global variable
# Test: Exit code is in a local variable
endbasic$ █
What do test cases look like?
Every test case has a section title describing what the test is about and various subsections to define the test scenario:
- A Source code block that is the input to the compiler.
- If compilation fails, a Compilation errors section with the error messages and nothing else afterwards.
- If compilation succeeds:
- A Disassembly section that contains the compiled bytecode.
- An optional Exit code section showing the program’s exit code, if different from zero.
- An Output section that contains any messages printed to the console by the executed program.
- A Runtime errors section that contains any errors from the executed program.
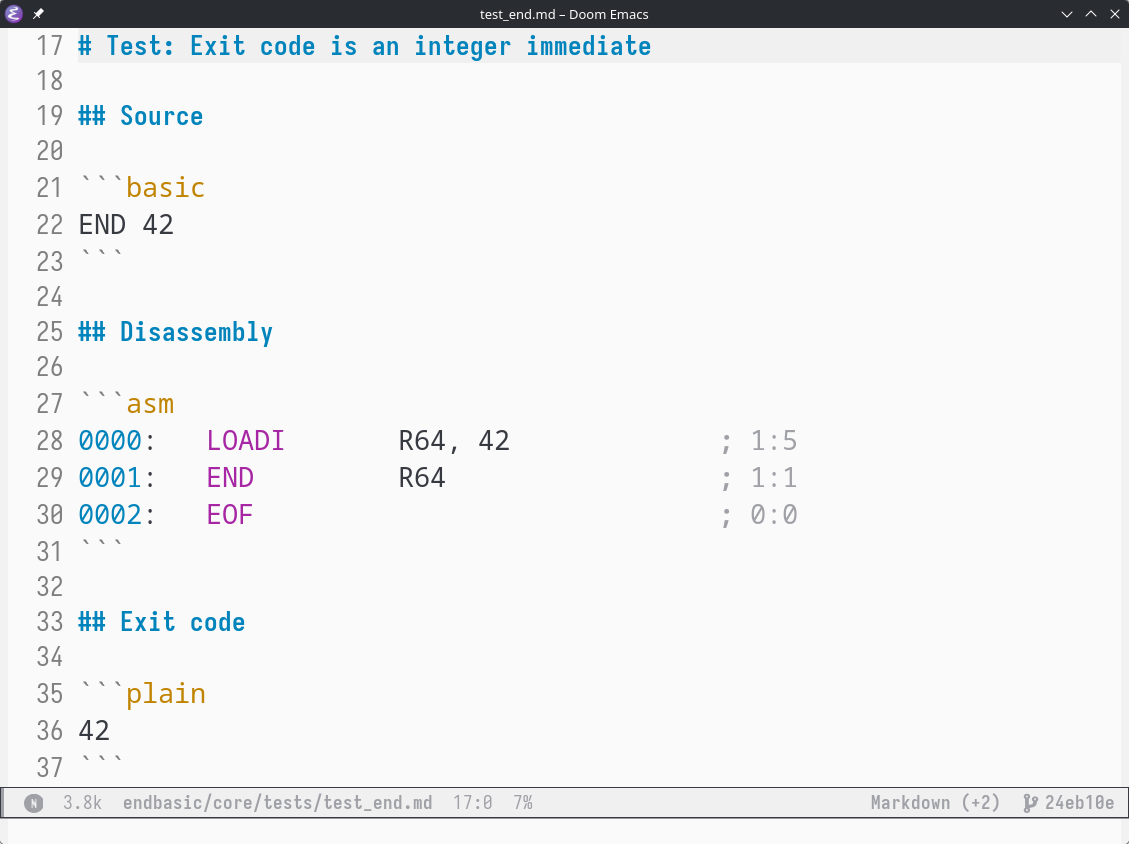
Here is a simple example validating the END command:
# Test: Exit code is an integer immediate
## Source
```basic
END 42
```
## Disassembly
```asm
0000: LOADI R64, 42 ; 1:5
0001: END R64 ; 1:1
0002: EOF ; 0:0
```
## Exit code
```plain
42
```
There is no section to validate the lexer nor parser internals right now but I’m considering to further extend the format and dump the AST too in order to simplify the tests for these components.
How do the tests run?
The driver for this test suite enumerates all Markdown files in the tests directory and processes them one at a time.
For each file, the driver extracts all test case titles and their Source subsections to compute all the test cases to execute. Once the driver has this subset of information from the Markdown files, the driver feeds each individual test case to the compiler and, if compilation succeeds, to the VM. All side-effects are captured and the driver emits a new Markdown file from scratch with the results of the test.
Once the driver has terminated producing a new version of the Markdown file for a test, the driver compares the produced file (actual) against the pre-recorded, checked-in version (golden). If they differ, the test fails and the driver uses the diff tool to print the differences.
And that’s it. Easy peasy, right? This keeps the driver super-simple as the only thing it has to do is parse a minimal subset of Markdown, and the diffs it produces are trivial to understand to a human.
Is this maintainable?
There are currently 448 test cases and 13k lines of Markdown in this test suite so maintaining them “by hand” is not an option. You wouldn’t want to implement an optimization to the compiler and then have to rewrite hundreds of disassembly chunks in the golden files to reflect the changes, would you?
The thing is that, due to the design described earlier, regenerating the golden files after a core change is easy: the driver is already doing exactly that to execute the tests! The trick is, simply put, to ask the driver to rewrite the golden file instead of producing an actual file by setting the REGEN=true environment variable. And voila: all golden files are regenerated in place. I can then use Git to validate the changes and commit them along with the actual code change.
Impressions so far?
Let’s start with the pros of this Markdown-based test suite framework:
It is much easier to work with than what I had before. I used to dread touching the compiler and VM of the previous EndBASIC core implementation because tweaking tens of tests was painful. Changes required me to fiddle with positions and deeply nested types, and now the tests are trivial to tweak and diff against previous state.
Pretty much any decent text editor has Markdown support, including formatting fenced code blocks. This makes it easy to skim through the test suite and modify the files and is actually the primary reason I used Markdown instead of a bespoke textual format.
LLMs can “learn” with ease. OK, fair, this is just a guess: I did not try the same prompt at the beginning of this article against the old core with its Rust-based tests, and maybe the LLMs would have done a good job at reverse-engineering the rules. But because the Markdown tests are so much easier to read by humans, I have to assume that they also are for LLMs.
And now, of course, some cons:
Regenerating the output of a test, or all tests, is way too easy. With the older Rust-based tests, I was forced to manually punch in things like line numbers and nested AST trees. This process forced me to think through the changes in detail. With the new approach… regenerating the golden files is trivial, so it’s easy to miss little mistakes in source positions or disassembled code.
Differences in disassembly are usually noisy and hard to review because every line carries an address and thus any new or deleted instruction will introduce offsets into all other addresses. I could of course choose to not include the instruction addresses in the dump, but they come in handy when manually validating jump targets, so it felt better to keep them around.
Rust cannot generate first-class test cases on the fly which means that the various test cases within a Markdown file are “invisible” to the driver: I can run them all or none, but regular test filtering via
cargo testdoesn’t apply. I was able to “expose” the different Markdown files as different Rust-native test cases, but this involves a hardcoded list of test files—which must be kept in sync with the files on disk, and so I mitigated the chances of divergence by adding a test that cross-references the two.This idea does not generalize well. The Markdown-based test suite presented here works well for components where end-to-end testing is favorable and, more importantly, cheap, but I wouldn’t recommend it for other scenarios. Keeping tests fast is a must for quick iteration.
And I think that’s about it. If the above feels too abstract, I encourage you to take a look at the driver, its helper code, and the directory with test suites.
Now that you have this new trick up your sleeve, what do you think?


Featured software
Featured posts
- Fast machines, slow machines
- EndBASIC 0.10: Core language, evolved
- Farewell, Microsoft; hello, Snowflake!
- Rust is hard, yes, but does it matter?
- Rust traits and dependency injection
- A year on Windows: Introduction
- Always be quitting
- How does Google keep build times low?
- How does Google avoid clean builds?
- Unit-testing a console app (a text editor)
- More...