
MVC but for non-UI apps
In MVC isn’t MVC, which hit the Hacker News front page overnight, Collin Donnell describes how the MVC design pattern that we use today isn’t really what was originally envisioned in 1979 by Tyrgve Reenskaug. This prompted me to think about how this architecture, if tweaked even further, maps pretty well to today’s designs of other kinds of programs, and I want to explore two cases in this post: web services and CLI apps. I know I promised a post on the task queuing system I have written in Rust, but that will have to wait for a couple more days.
June 20, 2023
·
Tags:
iii-iv, opinion, software
Continue reading (about
8 minutes)
Introducing db_logger
Over the last couple of weeks, I have been modernizing the codebase of the EndBASIC cloud service by applying many of the learnings I got from the development of EndTRACKER. The latter was a fork of the former and thus the foundations were the same, but as I iterated on the latter more recently, I got to refine my approach to writing a REST API in Rust.
During this refactoring process, there was a small piece of the system that routinely got in the way for various reasons. This piece was the “database logger”.
April 12, 2022
·
Tags:
db_logger, rust, software
Continue reading (about
3 minutes)
Encode your assumptions
The point of this post is simple and I’ll spoil it from the get go: every time you make an assumption in a piece of code, make such assumption explicit in the form of an assertion or error check. If you cannot do that (are you sure?), then write a detailed comment.
In fact, I’m exceedingly convinced that the amount of assertion-like checks in a piece of code is a good indicator of the programmer’s expertise.
February 7, 2019
·
Tags:
bazel, production-software, readability, software
Continue reading (about
4 minutes)

Hello, sandboxfs 0.1.0
I am pleased to announce that the first release of sandboxfs, 0.1.0, is finally here! You can download the sources and prebuilt binaries from the 0.1.0 release page and you can read the installation instructions for more details.
The journey to this first release has been a long one. sandboxfs was first conceived over two years ago, was first announced in August 2017, showed its first promising results in April 2018, and has been undergoing a rewrite from Go to Rust. (And by the way, this has been my 20% project at Google so rest assured that they are still possible!)
February 5, 2019
·
Tags:
bazel, featured, pkg_comp, sandboxctl, sandboxfs, software
Continue reading (about
7 minutes)
A few extra system calls... and you lose 1% build time
Blaze—the variant of Bazel used internally at Google—was originally designed to build the Google monorepo. One of the beauties of sticking to a monorepo is code reuse, but this has the unfortunate side-effect of dependency bloat. As a result, Bazel and Blaze have evolved to support ever-increasingly-bigger pieces of software.
The growth of the projects built by Bazel and Blaze has had the unsurprising consequence that our engineers all now have high-end workstations with access to massive amounts of distributed resources. And, as you can imagine, this has had an impact in the design of Blaze: many chunks of our codebase can—and do—assume that everyone has powerful hardware. These assumptions break down as soon as you move into Bazel’s open source land: while knowing where the product really runs is out of hand, we can safely assume it is certainly being used on slower hardware.
April 30, 2018
·
Tags:
bazel, google, monorepo, software
Continue reading (about
4 minutes)
Preliminary sandboxfs support in Bazel
During the summer of last year, I hosted an intern who implemented sandboxfs: a FUSE-based file system that exposes an arbitrary view of the host’s file system under the mount point. At the end of his internship, we had a functional sandboxfs implementation and some draft patches for integration in Bazel.
The goal of sandboxfs in the context of Bazel is to improve the performance of builds when action sandboxing is enabled. The way in which we try to do so is by replacing the costly process of setting up the file system for each action using symlinks with a file system that does so “instantaneously”.
April 13, 2018
·
Tags:
bazel, google, sandboxfs, software
Continue reading (about
2 minutes)
Stick to your project's core language in your tests
This post is a short, generalized summary of the preceeding two. I believe those two posts put readers off due to their massive length and the fact that they were seemingly tied to Bazel and Java, thus failing to communicate the larger point I wanted to make. Let’s try to distill their key points here in a language- and project-agnostic manner.
March 27, 2018
·
Tags:
bazel, featured, google, software
Continue reading (about
3 minutes)
A case for writing Bazel's integration tests in Java, part 2
In part 1 of this series, I made the case that you should run away from the shell when writing integration tests for your software and that you should embrace the primary language of your project to write those.
Depending on the language you are using, doing this will mean significant more work upfront to lay out the foundations for your tests, but this work will pay off. You may also feel that the tests could be more verbose than if they were in shell, though that’s not necessarily the case.
March 19, 2018
·
Tags:
bazel, google, sandboxfs, software
Continue reading (about
12 minutes)
A case for writing Bazel's integration tests in Java, part 1
My latest developer productivity rant thesis is that integration tests should be written in the exact same language as the thing they test. Specifically, not shell.
This theory applies mostly to tests that verify infrastructure software like servers or command line tools. It is too easy to fall into the trap of using the shell because it feels like the natural choice to interact with tools. But I argue that this is a big mistake that hurts the long-term health of the project, and once trapped, it’s hard to escape.
March 16, 2018
·
Tags:
bazel, google, software
Continue reading (about
14 minutes)
Don't rollback rollbacks
In a version control system, a rollback is a type of change that undoes the effects of a previous commit. In essence, a rollback is a commit that applies the inverse diff of another commit.
At Google, our tools make it trivial to create rollbacks for a given changelist or CL. (A CL is similar to a commit but can be either pending—in review—or submitted.) Making it trivial to create rollback CLs is important in a culture where the standard upon encountering a problem is “rollback first, ask questions later” because it removes friction from the process of backing out problematic changes.
March 5, 2018
·
Tags:
google, software
Continue reading (about
5 minutes)
Fighting execs via sandboxfs on macOS
Since the announcement of sandboxfs a few weeks ago, I’ve been stabilizing its integration with Bazel as a new sandboxing technique. As part of this work, I encountered issues when macOS was immediately killing signed binaries executed through the sandbox. Read on for the long troubleshooting process and the surprising trivial solution.
October 6, 2017
·
Tags:
sandboxfs, software
Continue reading (about
10 minutes)
Introducing sandboxfs
sandboxfs is a FUSE-based file system that exposes an arbitrary view of the
host’s file system under the mount point, and offers access controls that
differ from those of the host. You can think of sandboxfs as an advanced
version of bindfs (or mount --bind or mount_null(8)
depending on your system) in which you can combine and nest directories under
an arbitrary layout.
The primary use case for this project is to provide a better file system sandboxing technique for the Bazel build system. The goal here is to run each build action (think compiler invocation) in a sandbox so that its inputs and outputs are tightly controlled, and sandboxfs attempts to do this in a more efficient manner than the current symlinks-based implementation.
August 25, 2017
·
Tags:
bazel, pkg_comp, sandboxfs, software, sourcachefs
Continue reading (about
2 minutes)
Introducing sourcachefs
Announcing the launch of sourcachefs, a FUSE-based persistent caching layer.
July 30, 2017
·
Tags:
software, sourcachefs
Continue reading (about
2 minutes)
Easy pkgsrc on macOS with pkg_comp 2.0
This is a tutorial to guide you through the shiny new pkg_comp 2.0 on macOS using the macOS-specific self-installer.
Goals: to use pkg_comp 2.0 to build a binary repository of all the packages you are interested in; to keep the repository fresh on a daily basis; and to use that repository with pkgin to maintain your macOS system up-to-date and secure.
February 23, 2017
·
Tags:
macos, pkg_comp, sandboxctl, software, tutorial
Continue reading (about
6 minutes)
Keeping NetBSD up-to-date with pkg_comp 2.0
This is a tutorial to guide you through the shiny new pkg_comp 2.0 on NetBSD.
Goals: to use pkg_comp 2.0 to build a binary repository of all the packages you are interested in; to keep the repository fresh on a daily basis; and to use that repository with pkgin to maintain your NetBSD system up-to-date and secure.
February 18, 2017
·
Tags:
netbsd, pkg_comp, sandboxctl, software, tutorial
Continue reading (about
6 minutes)
Introducing pkg_comp 2.0 (and sandboxctl 1.0)
Announcing the launch of pkg_comp 2.0, how this differs from the 1.x series, why there was a rewrite, what sandboxctl 1.0 is, and more.
February 17, 2017
·
Tags:
featured, pkg_comp, sandboxctl, software
Continue reading (about
7 minutes)
Visual Studio Code: A modern editor
On April 14th, 2016, Microsoft announced the 1.0 release of their open-source Visual Studio Code (VSCode) editor. I’ve been drive-testing it for a few months and have been quite pleased with it, so here go my impressions.
How did I get here?
Let’s backtrack a bit first. I’ve been a Vim and Emacs user for many years. Yes, I use both regularly depending on what I have to achieve. For me, Vim shines in doing quick single-file changes and repetitive edits through many files, while Emacs shines in long-lived coding sessions that involve numerous open buffers. These editors are well-suited to my remote-based coding workflow because they run just fine in the terminal. However, sometimes I just would like to take advantage of the desktop environment and the GUI of these two editors on OS X… err.. sucks… so I’ve been wanting to find something else.
April 19, 2016
·
Tags:
development, software, workflow
Continue reading (about
6 minutes)
A look at Go from a newbie's perspective
I confess I am late to the game: the Go programming language came out in 2009 and I had not had the chance to go all in for a real project until two weeks ago. Here is a summary of my experience. Spoiler alert: I’m truly pleased.
The project
What I set out to build is a read-only caching file system to try to solve the problems I presented in my previous analysis of large builds on SSHFS. The reasons I chose Go are simple: I had to write a low-level system component and, in theory, Go excels at this; I did not want to use plain C; Go had the necessary bindings (for FUSE and SQLite); and, heck, I just wanted to try it out!
March 22, 2016
·
Tags:
featured, go, software
Continue reading (about
10 minutes)
Those pesky Makefiles
As a software developer, you have probably disregarded the build system of your project—those pesky Makefiles—as unimportant. You have probably “chosen” to use the de-facto build tool make(1). And you have probably hacked your way around until things “seemingly worked”.
But hang on a second. Those build files are way more important than you may think and deserve a wee bit more attention.
March 2, 2016
·
Tags:
software
Continue reading (about
7 minutes)
Analysis of SSHFS performance for large builds
Last week, I spent some time looking at the feasibility of using SSHFS on OS X to access Google’s centralized source tree for the purpose of issuing local builds. My goals were two-fold: first, to avoid having to “clone” the large source code of the apps I wanted to build; and, second, to avoid having to port the source file system (a FUSE module) to the Mac.
What I found highlights that SSHFS is not the right choice for locally building a remote source tree. That said, the overall study process was interesting, fun, and I am now tempted to make SSHFS viable for this use case. Read on for the details.
February 17, 2016
·
Tags:
software, sourcachefs
Continue reading (about
11 minutes)
Introducing Nudgy Timer
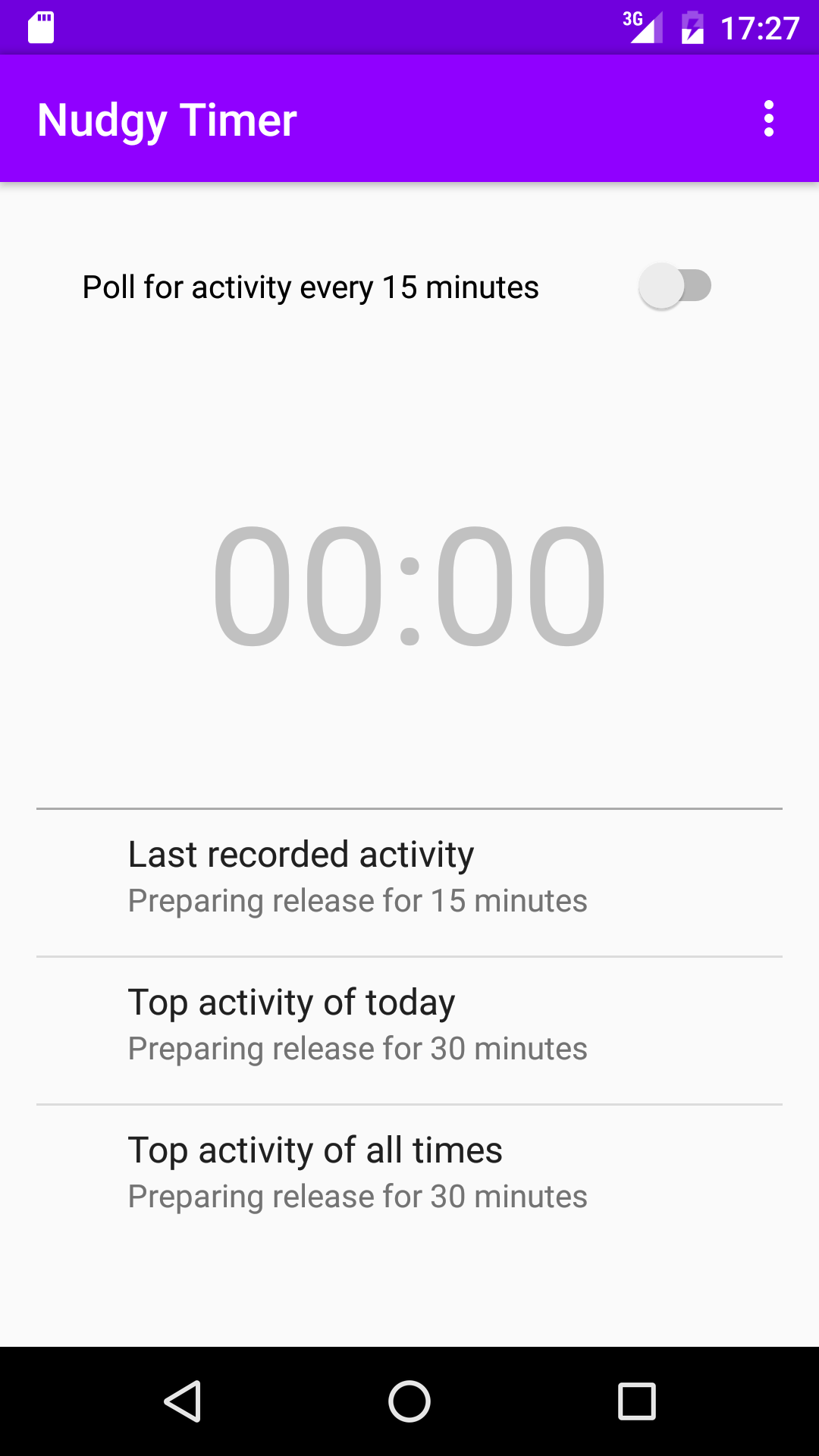
For the last two years, I had been meaning to write an Android app just for the sake of it. I had attempted to do so in short chunks of “free time”, but that never played out well: I had to force myself to sit down for a few hours straight to fight Android Studio and overcome the initial difficulties in coding for an unknown platform. That’s why, during the last Thanksgiving week, I took three days off of work to focus on writing my first Android app. The goal was to get a basic app that could later be built on iteratively as open source. The specifics of the app did not matter much for this exercise, but I had a simple idea in mind.
December 17, 2015
·
Tags:
nudgytimer, software
Continue reading (about
3 minutes)
Introducing Markdown2Social
Markdown2Social is a new open-source tool, originally written at Google for Google-internal posts, that converts Markdown documents to Google+ posts.
December 10, 2015
·
Tags:
markdown, markdown2social, software
Continue reading (about
1 minute)
Compilers in the (BSD) base system
A commonly held axiom in the BSD community is that the C compiler belongs in the base system. “This is how things have been since the beginning of time and they define the way BSD systems are”, the proposition goes.
But why is that? What makes “having a compiler in base” a BSD system? Why is the compiler a necessary part of the base system? Hold on, is it? Could we take it out?
October 23, 2015
·
Tags:
bsd, compilers, essay, featured, software
Continue reading (about
5 minutes)
How to commit a code hack and not perish along the way
You are the developer in charge to resolve a problem and have prepared a changelist to fix the bug. You need the changelist to be reviewed by someone else before checkin. Your changelist is an ugly hack.
What kind of response are you gonna get from your reviewer? Well as with everything: it depends!
(Cover image courtesy of http://www.startupstockphotos.com/.)
If you have:
- clearly stated upfront that the changelist is a hack,
- explained how it is a hack,
- justified that the hack is the right thing to do at this moment, and
- outlined what the real solution to get rid of the hack would be
then your reviewer will most likely just accept the change without fuss (!) and will proceed to review its contents per se. But if you miss any of those steps, then your reviewer is going to be super-critical about your changelist and any further related changes you may want to commit.
June 19, 2015
·
Tags:
best-practices, development, essay, featured, software
Continue reading (about
6 minutes)
On Bazel and Open Source
This is a rare post because I don’t usually talk about Google stuff here, and this post is about Bazel: a tool recently published by Google. Why? Because I love its internal counterpart, Blaze, and believe that Bazel has the potential to be one of the best build tools if it is not already.
However, Bazel currently has some shortcomings to cater to a certain kind of important projects in the open source ecosystem: the projects that form the foundation of open source operating systems. This post is, exclusively, about this kind of project.
April 14, 2015
·
Tags:
bazel, featured, google, software
Continue reading (about
17 minutes)
Mailing lists for commit notifications
The project I'm currently working on at university uses Subversion as its version control system. Unfortunately, the project itself has no mailing list to receive notifications on every commit, and the managers refuse to set this up. They do not see the value of such a list and they are scared of it because they probably assume that everyone ought to be subscribed to it.
Having worked on projects that have a commit notification mailing list available, I strongly advise to have such a list anytime you have more than one developer working on a project[1]. Bonus points if every commit message comes with a bundled copy of the change's diff (in unified form!). This list must be independent from the regular development mailing list and it must be opt-in: i.e. never subscribe anyone by default, let themselves subscribe if they want to! Not everyone will need to receive this information, but it comes very useful... and it's extremely valuable for the project managers themselves!
Why is this useful? Being subscribed to the commit notification mailing list, it is extremely easy to know what is going on on the project[2]. It is also really easy to review the code submissions as soon as they are made which, with proper reviews by other developers, trains the authors and improves their skills. And if the revision diff is inlined, it is trivial to pinpoint mistakes in it (be them style errors, subtle bugs, or serious design problems) by replying to the email.
So, to my current project managers: if you read me, here is a wish-list item. And, for everyone else, if you need to set up a new project, consider creating this mailing list as soon as possible. Maybe few developers will subscribe to it, but those that do will pay attention and will provide very valuable feedback in the form of replies.
1: Shame on me for not having such a mailing list for ATF. Haven't investigated how to do so with Monotone.
2: Of course, the developers must be conscious to commit early and often, and to provide well-formed changesets: i.e. self-contained and with descriptive logs.
May 13, 2009
·
Tags:
software
Continue reading (about
2 minutes)
Software bloat, 2
A long while ago — just before buying the MacBook Pro — I already complained about software bloat. A year and two months later, it is time to complain again.
I am thinking on renewing my MacBook Pro assuming I can sell this one for a good price. The reasons for this are to get slightly better hardware (more disk, better GPU and maybe 4GB of RAM) and software updates. The problem is: if I am able to find a buyer, I will be left without a computer for some days, and that's not a good scenario. I certainly don't want to order the new one without being certain that I will be paid enough for the current one.
So yesterday I started assembling some old components I had lying around aiming at having an old but functional computer to work with. But today I realized that I also had the PlayStation 3 with Fedora 8 already installed, and that it'd be enough to use as a desktop for a week or so. I had trimmed down the installation to the bare minimum so that it'd boot as fast as possible and to leave free resources for testing Cell-related stuff. But if I wanted to use the PS3 as a desktop, I needed, for example, GNOME.
Ew. Doing a yum groupinstall "GNOME Desktop Environment" took quite a while, and not because of the network connection. But even if we leave that aside, starting the environment was painful. Really painful. And Mono was not there, at all! It is amazing how unusable the desktop is with "only" 256MB of RAM; the machine is constantly going to swap, and the disk being slow does not help either. I still remember the days when 256MB was a lot, and desktop machines were snappy enough with only half of that, or even less.
OK, so GNOME is a lot for 256MB of RAM. I am now writing this from the PS3 itself running WindowMaker. Which unfortunately does not solve all the problems — and the biggest one is that it is not a desktop environment. Firefox also requires lots of resources to start, and doing something else in the background still makes the machine use swap. (Note that I have disabled almost all of the system services enabled by default in Fedora, including SELinux.)
If I finally sell my MBP, this will certainly be enough for a few days... but it's a pity to see how unusable it is. (Yeah, by today's standards, the PS3 is extremely short on RAM, I know, but GNOME used to run quite well with this amount of RAM just a few years ago.)
February 28, 2008
·
Tags:
bloat, gnome, ps3, software
Continue reading (about
3 minutes)
Software bloat
A bit more than three years ago, I renewed my main machine and bought an Athlon XP 2600+ with 512MB of RAM and a 80GB hard disk. The speed boost I noticed in games, builds and the overall system usage was incredible — I was coming from a Pentium II 233 with 384MB of RAM.
With the change, I was finally able to switch from plain window managers to desktop environments (alternating KDE and GNOME from time to time) and still keep a usable machine. I was also able to play the games of that era at high resolutions. And, what benefited me more, the build times of packages and NetBSD itself were cut by more than a half. For example, it previously needed between 6 to 7 hours to do a full NetBSD release build and, after the switch, it barely took 2. On the pkgsrc side, building some packages was almost instantaneous because the machine processed both the infrastructure and the source builds like crazy.
But time passes and nowadays the machine feels extremely sluggish. And you know that hardware does not degrade like this so it's easy to conclude it's software's fault. (Thank God I've done some upgrades on the hardware, like doubling the memory, replacing the video card and adding a faster hard disk.)
I'm currently running Kubuntu 6.10 and KDE is desperately slow in some situations; of course GNOME has its critical scenarios too. (Well... it is not that slow, but responsiveness is, and that makes a big amount of the final experience.) The problem is they behaved much better in the past yet I, as a desktop user, haven't noticed any great usability improvement that is worth such speed differences. As a side note: I know the developers of both projects try their best to optimize the code — kudos to them! — but this is how I see it in my machine.
Another data point, this time more objective than the previous one. Remember I mentioned NetBSD took less than 2 hours to build? Guess what. It now takes 5 to 6 hours to build a full release; it's as if I went back in time 3 years! Or take pkgsrc: the infrastructure is now very, very slow; in some packages, it takes more time than the program's build itself.
I could continue this rant but... it'd drive nowhere. Please do not take it as something against NetBSD, pkgsrc and KDE in particular. I've taken these three projects to illustrate the issue because they are the ones I can compare to the software I used when I bought the machine. I'm sure all other software suffers from slowdowns.
Anyway, three years seem to be too much for a machine. Sometimes I think developers should be banned fast machines because, usually, they are the ones with the fastest machines. This makes them not notice the slowdowns as much as end users do. Kind of joking.
December 9, 2006
·
Tags:
bloat, rant, software
Continue reading (about
3 minutes)

Featured software
Featured posts
- Fast machines, slow machines
- EndBASIC 0.10: Core language, evolved
- Farewell, Microsoft; hello, Snowflake!
- Rust is hard, yes, but does it matter?
- Rust traits and dependency injection
- A year on Windows: Introduction
- Always be quitting
- How does Google keep build times low?
- How does Google avoid clean builds?
- Unit-testing a console app (a text editor)
- More...
